Code
tsibble |>
model(
baseline = decomposition_model(
STL(y ~ trend(window = NULL) + season(window = "periodic"), robust = TRUE),
RW(season_adjust ~ drift()),
SNAIVE(season_year)
)
)In Module 1, you built your first complete forecasting model. That model used:
tsibble |>
model(
baseline = decomposition_model(
STL(y ~ trend(window = NULL) + season(window = "periodic"), robust = TRUE),
RW(season_adjust ~ drift()),
SNAIVE(season_year)
)
)This is your benchmark. Every model we build from now on must beat it.
That’s a solid start — but the Drift method is very simple: it just extrapolates the last observed average growth rate forever. What if the trend is slowing down? Accelerating? Or changing direction?
This module introduces Exponential Smoothing (ETS) models — a smarter way to model the trend-cycle component (and eventually, the seasonal component too).
| Component | Module 1 (Baseline) | Module 2 (ETS upgrade) |
|---|---|---|
| Trend-cycle | Drift (RW + drift) | ETS (adaptive smoothing) |
| Seasonal | SNAIVE | SNAIVE (for now) |
| Decomposition | STL | STL (for now) |
We’re making the trend-cycle component smarter. Same architecture, better engine.
Exponential smoothing methods are still relatively simple: they’re simply weighted averages from historical data.
The exponential smoothing method is a compromise between the mean and naïve methods. It uses all historical data, but it assigns exponentially decreasing weights to older observations.
The smoothing parameter \alpha controls the rate of decrease:
\hat{y}_{T+1 | T}= \alpha y_{T} + \alpha(1-\alpha) y_{T-1} + \alpha(1-\alpha)^{2} y_{T-2} + \ldots
where 0\leq \alpha \leq1 is the smoothing parameter.
| \alpha = 0.2 | \alpha = 0.4 | \alpha = 0.6 | \alpha = 0.8 | |
|---|---|---|---|---|
| y_t | 0.2000 | 0.4000 | 0.6000 | 0.8000 |
| y_{t-1} | 0.1600 | 0.2400 | 0.2400 | 0.1600 |
| y_{t-2} | 0.1280 | 0.1440 | 0.0960 | 0.0320 |
| y_{t-3} | 0.1024 | 0.0864 | 0.0384 | 0.0064 |
| y_{t-4} | 0.0819 | 0.0518 | 0.0154 | 0.0013 |
| y_{t-5} | 0.0655 | 0.0311 | 0.0061 | 0.0003 |
\alpha can be thought of as the memory of the time series: The smaller the value of \alpha, the longer the memory (i.e., the more past observations are taken into account).
Conversely, a larger value of \alpha means a shorter memory, with more emphasis on recent observations. See Table 1 for some examples.
\begin{aligned} \text{Forecast equation} \quad & \hat{y}_{t+h|t} = \ell_t \\ \text{Smoothing equation} \quad & \ell_t = \alpha y_t + (1-\alpha)\ell_{t-1} \end{aligned}
where \ell_t is the level at time t.
SES has a flat forecast function, so it is appropriate for data with no trend or seasonal pattern.
algeria_economy <- global_economy |>
filter(Country == "Algeria")
algeria_economy |>
autoplot(Exports)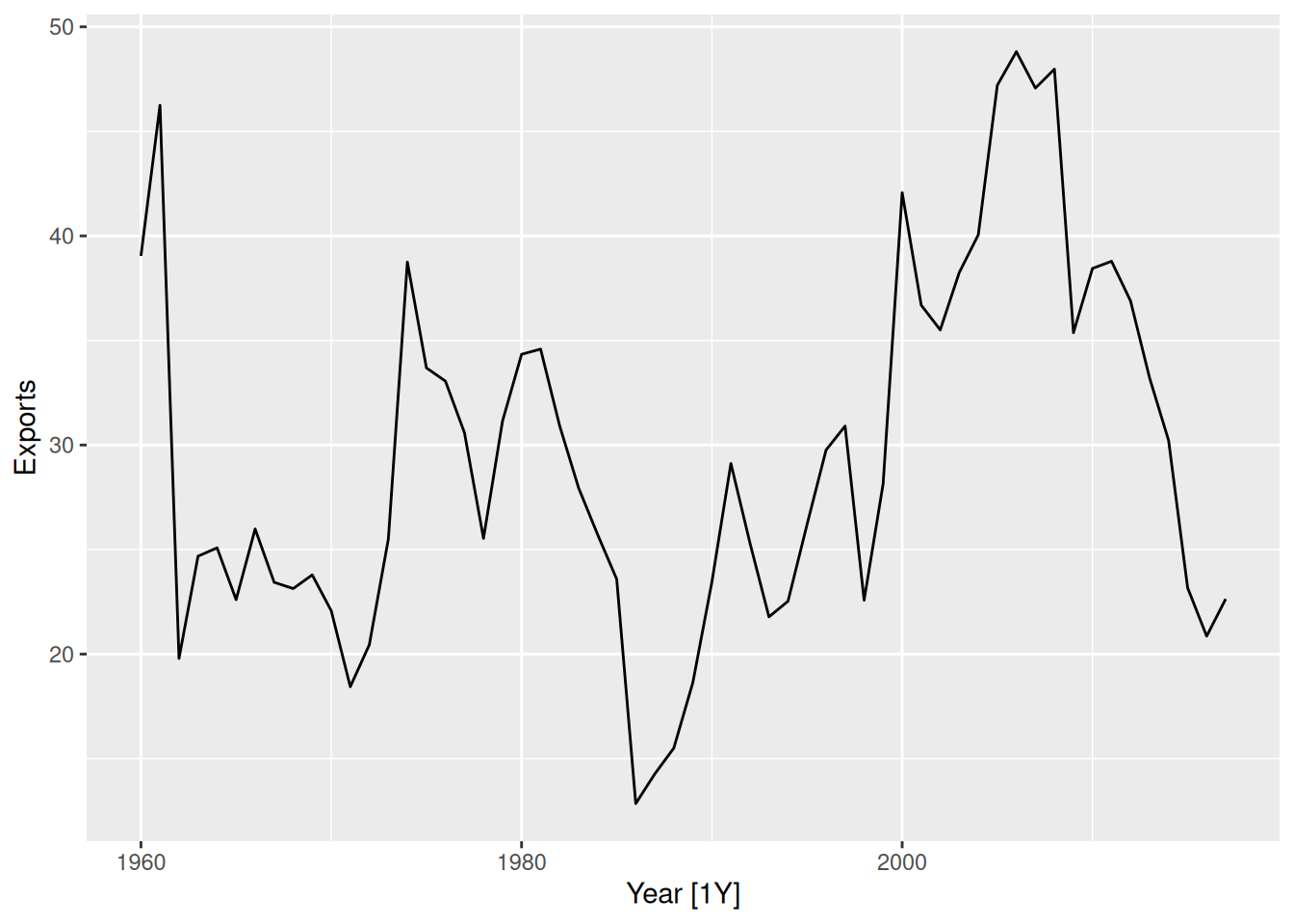
alg_fit <- algeria_economy |>
model(
1 SES = ETS(Exports ~ error("A") + trend("N") + season("N")),
Naive = NAIVE(Exports)
)
alg_fc <- alg_fit |>
forecast(h = 5)trend("N") and season("N") to indicate that we want a simple exponential smoothing (SES) model, which assumes no trend and no seasonality. The model will estimate the smoothing parameter \alpha automatically.
The mean and naïve methods are typically the best fit as benchmark methods when using SES.
report() of a model
alg_fit |>
select(SES) |>
1 report()report() function allows us to see a model’s report (the time series modeled, the model used, the estimated parameters, and more). It needs a 1 \times 1 dimension mable1.
Series: Exports
Model: ETS(A,N,N)
Smoothing parameters:
alpha = 0.8399875
Initial states:
l[0]
39.539
sigma^2: 35.6301
AIC AICc BIC
446.7154 447.1599 452.8968 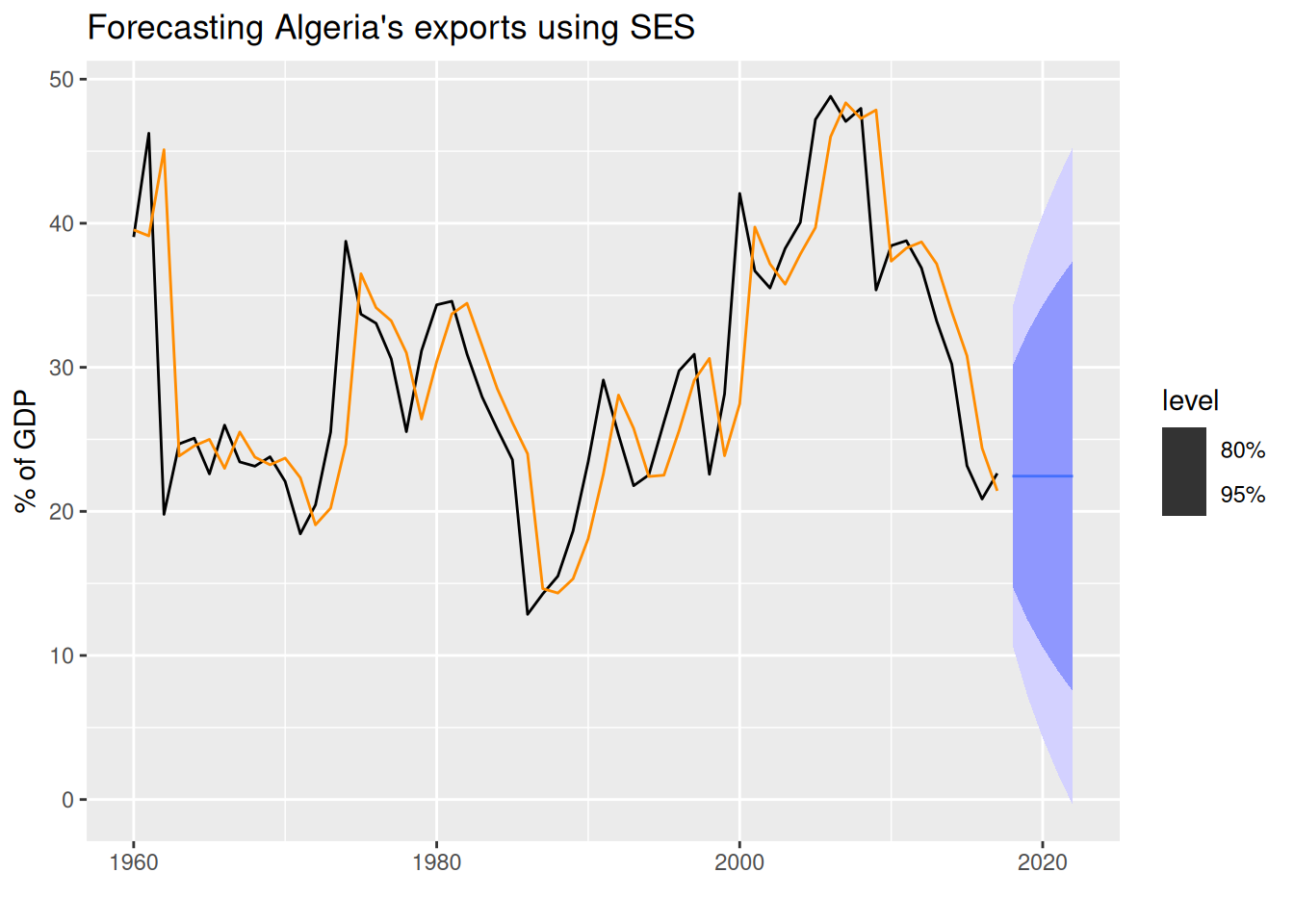
Comparing the SES and Naive forecasts:
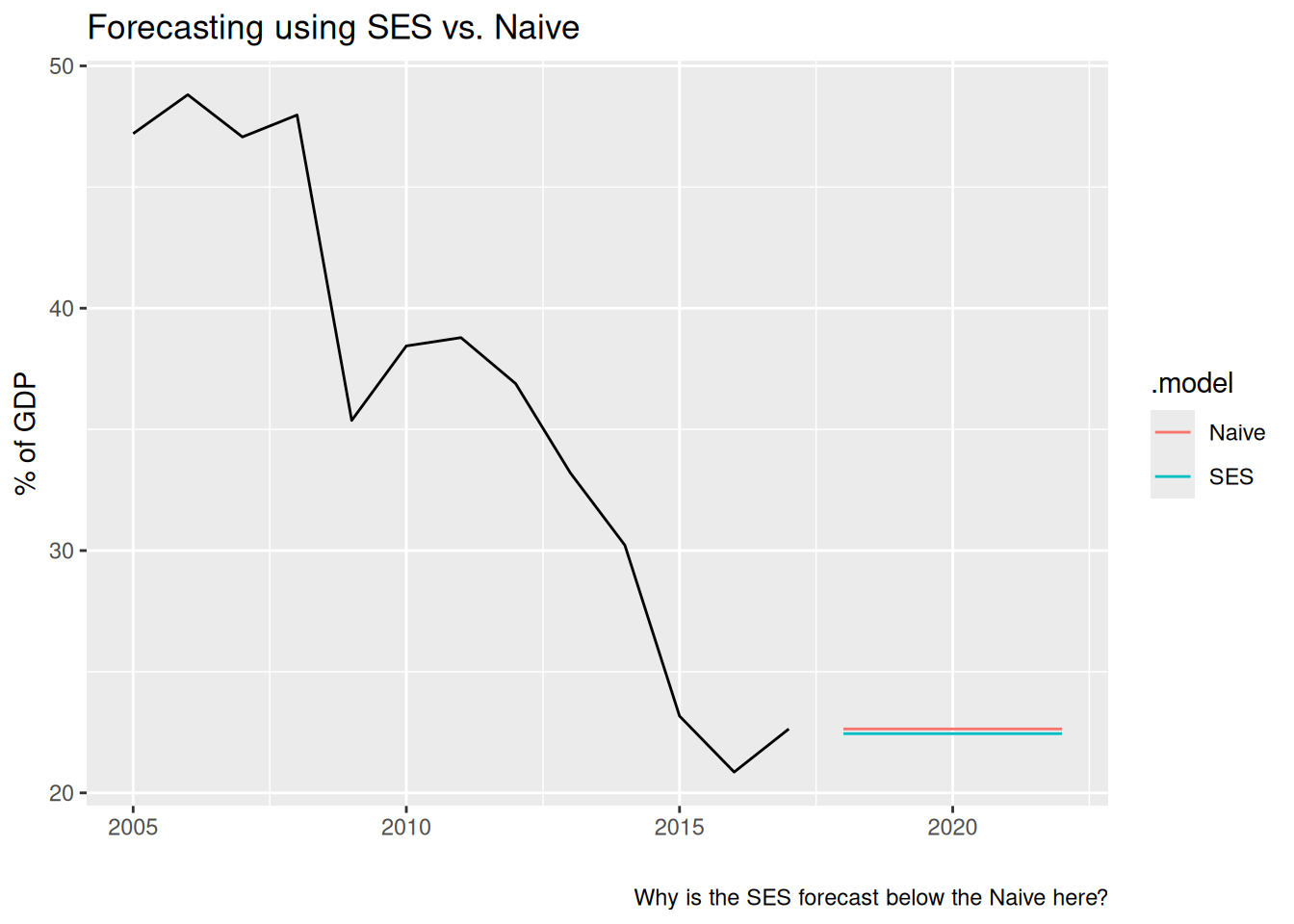
We can extend SES models to allow our forecasts to include trend in the data. We need to add a new smoothing parameter \beta^*, and its corresponding smoothing equation:
\begin{aligned} \text{Forecast equation} \quad & \hat{y}_{t+h|t} = \ell_t + hb_t \\ \text{Level equation} \quad & \ell_t = \alpha y_t + (1-\alpha)\ell_{t-1}\\ \text{Trend equation} \quad & b_t = \beta^*(\ell_t - \ell_{t-1}) + (1-\beta^*)b_{t-1} \end{aligned}
where b_t is the growth (or slope) at time t.
Let’s see an example using Holt’s linear trend method to forecast Brazil’s population.
bra_economy <- global_economy |>
filter(Code == "BRA") |>
mutate(Pop = Population / 1e6)
bra_economy |>
autoplot(Pop)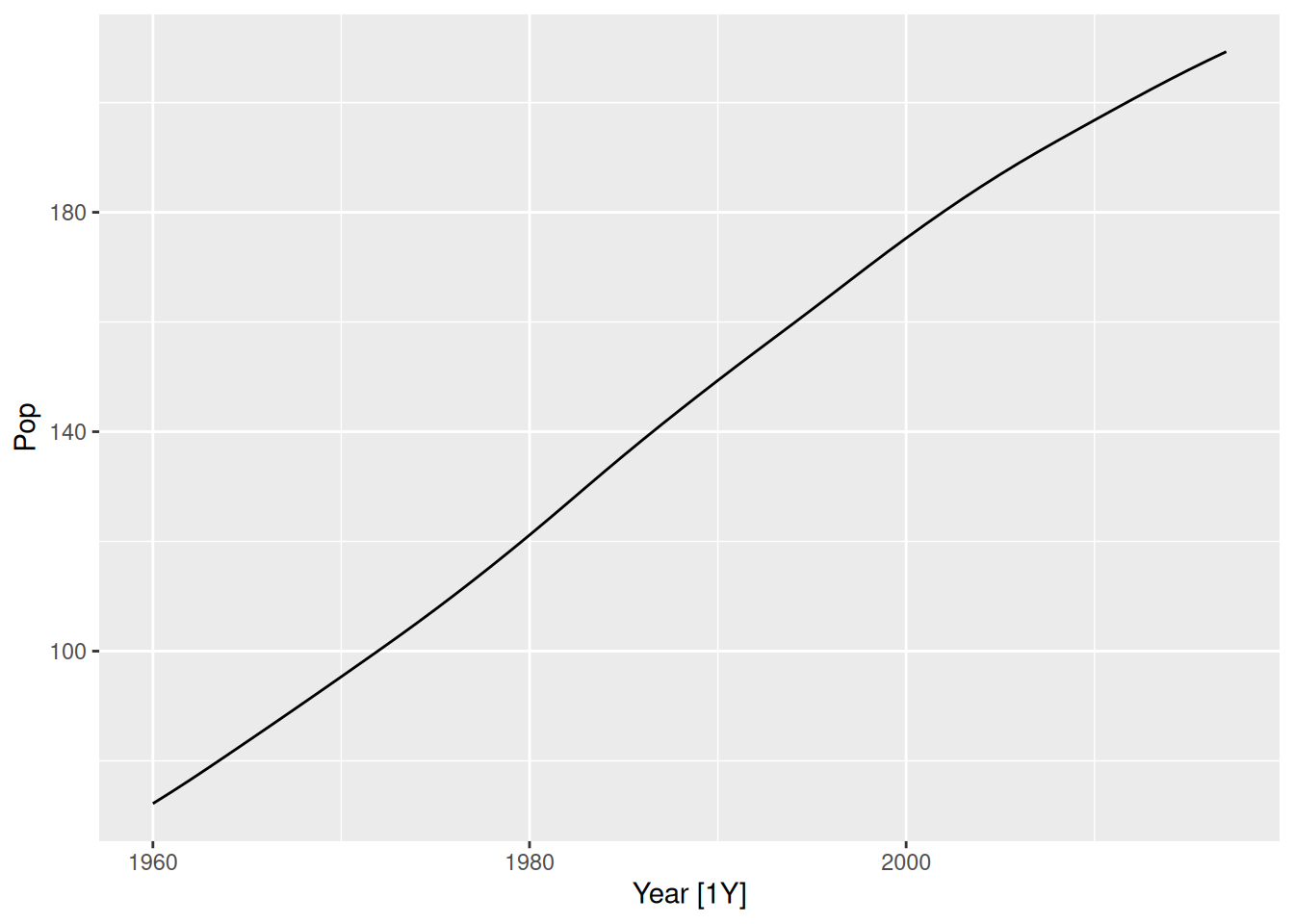
bra_fit <- bra_economy |>
model(
1 Holt = ETS(Pop ~ error("A") + trend("A") + season("N")),
Drift = RW(Pop ~ drift())
)
bra_fit |>
select(Holt) |>
report()
bra_fc <- bra_fit |>
forecast(h = 15)
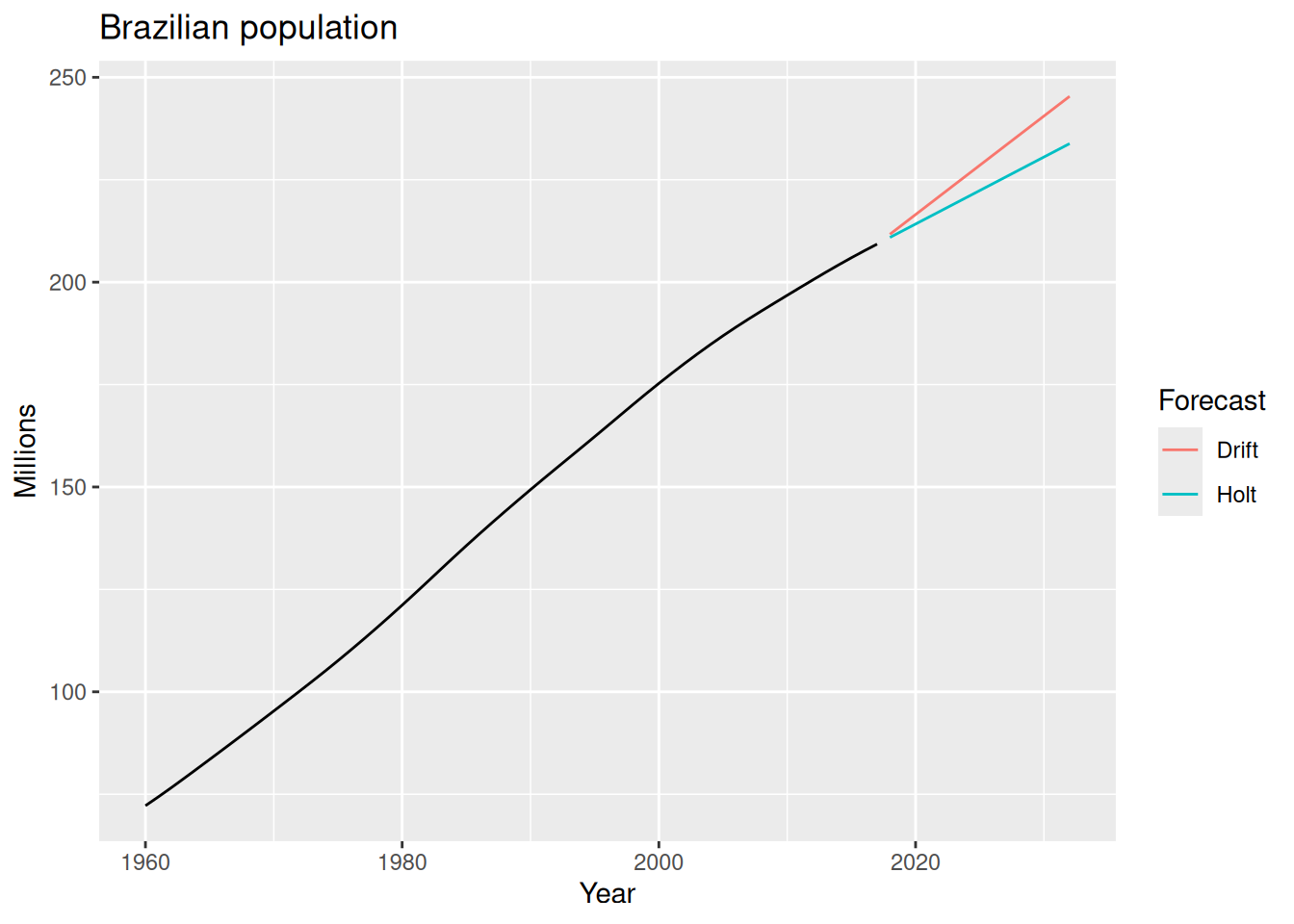
bra_fc |>
autoplot(bra_economy, level = NULL) +
labs(title = "Brazilian population",
y = "Millions") +
guides(colour = guide_legend(title = "Forecast"))trend("A") to indicate that we want a linear trend. The model will estimate the smoothing parameters \alpha and \beta^* automatically.
Series: Pop
Model: ETS(A,A,N)
Smoothing parameters:
alpha = 0.9999
beta = 0.9998999
Initial states:
l[0] b[0]
70.06297 2.132884
sigma^2: 0.0021
AIC AICc BIC
-115.2553 -114.1014 -104.9531 Holt’s linear trend method assume that the trend will continue indefinitely at the same rate. However, in many real-world scenarios, this assumption may not hold true. This methods tend to overestimate (or underestimate) long-term forecasts when the trend is strong.
We can include a damping parameter \phi, which reduces the trend over time.
\begin{aligned} \text{Forecast equation} \quad & \hat{y}_{t+h|t} = \ell_t + (\phi + \phi^2 + \ldots + \phi^h) b_t \\ \text{Level equation} \quad & \ell_t = \alpha y_t + (1 - \alpha) (\ell_{t-1} + \phi b_{t-1}) \\ \text{Trend equation} \quad & b_t = \beta^*(\ell_t-\ell_{t-1}) + (1-\beta^*)\phi b_{t-1} \end{aligned}
where 0 < \phi < 12 is the damping parameter.
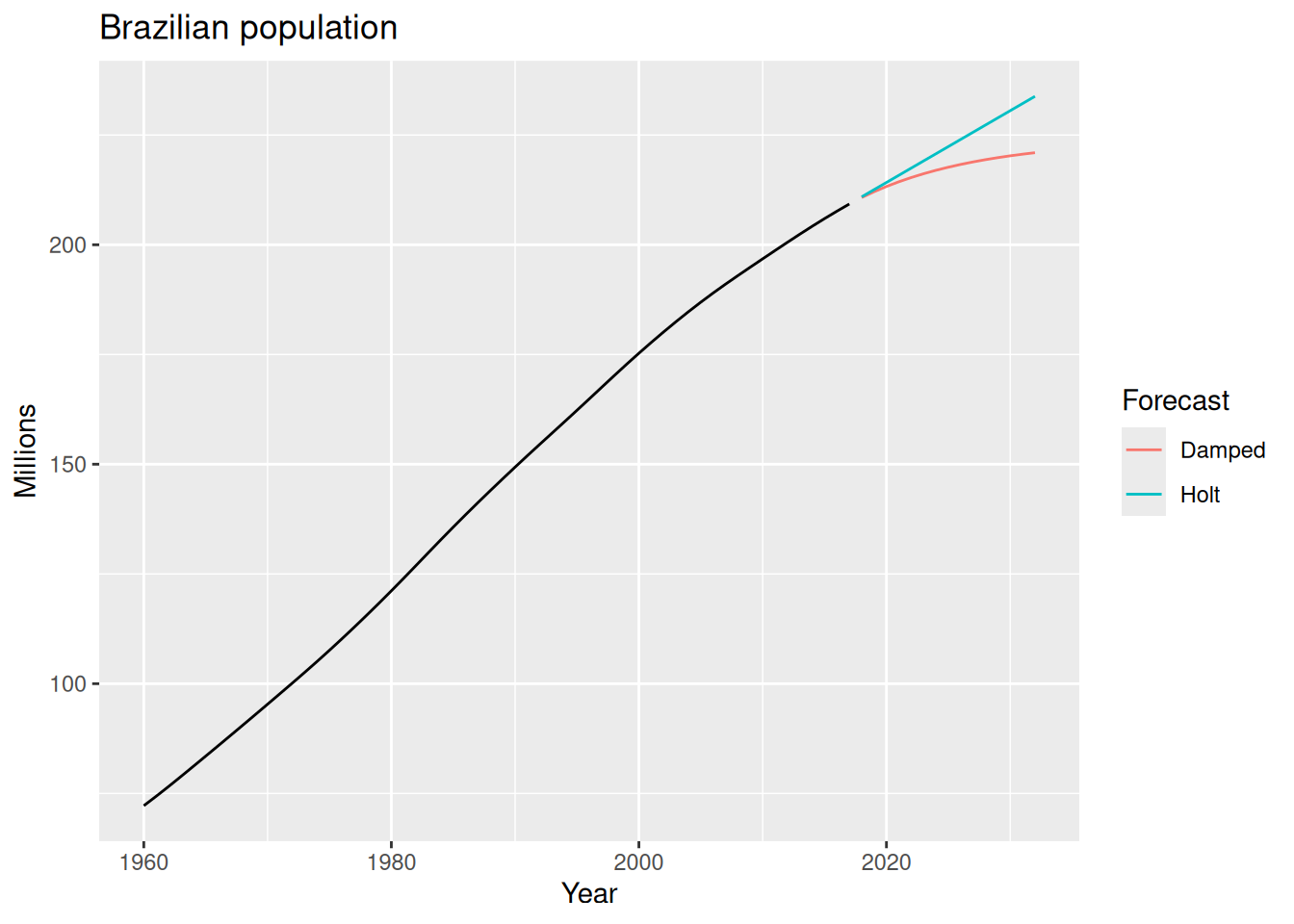
bra_economy |>
model(
Holt = ETS(Pop ~ error("A") + trend("A") + season("N")),
1 Damped = ETS(Pop ~ error("A") + trend("Ad", phi = 0.9) + season("N"))
) |>
forecast(h = 15) |>
autoplot(bra_economy, level = NULL) +
labs(title = "Brazilian population",
y = "Millions") +
guides(colour = guide_legend(title = "Forecast"))trend("Ad") to indicate that we want a damped trend, and phi = 0.9 sets the damping parameter to 0.9. We could also let the model estimate \phi automatically by omitting the phi argument.
\begin{aligned} \text{Forecast equation} \quad & \hat{y}_{t+h|t} = \ell_t + hb_t + s_{t+h-m(k+1)} \\ \text{Level equation} \quad & \ell_t = \alpha (y_t - s_{t-m}) + (1 - \alpha) (\ell_{t-1} + b_{t-1}) \\ \text{Trend equation} \quad & b_t = \beta^*(\ell_t-\ell_{t-1}) + (1-\beta^*) b_{t-1} \\ \text{Seasonal equation} \quad & s_t = \gamma(y_t - \ell_{t-1} - b_{t-1}) + (1-\gamma)s_{t-m} \end{aligned}
where s_t is the seasonal component at time t, m is the period of the seasonality3, and k = \lfloor (h-1)/m \rfloor.
\begin{aligned} \text{Forecast equation} \quad & \hat{y}_{t+h|t} = (\ell_t + hb_t) s_{t+h-m(k+1)} \\ \text{Level equation} \quad & \ell_t = \alpha \frac{y_t}{s_{t-m}} + (1 - \alpha)(\ell_{t-1} + b_{t-1}) \\ \text{Trend equation} \quad & b_t = \beta^*(\ell_t-\ell_{t-1}) + (1-\beta^*) b_{t-1} \\ \text{Seasonal equation} \quad & s_t = \gamma \frac{y_t}{\ell_{t-1} + b_{t-1}} + (1-\gamma)s_{t-m} \end{aligned}
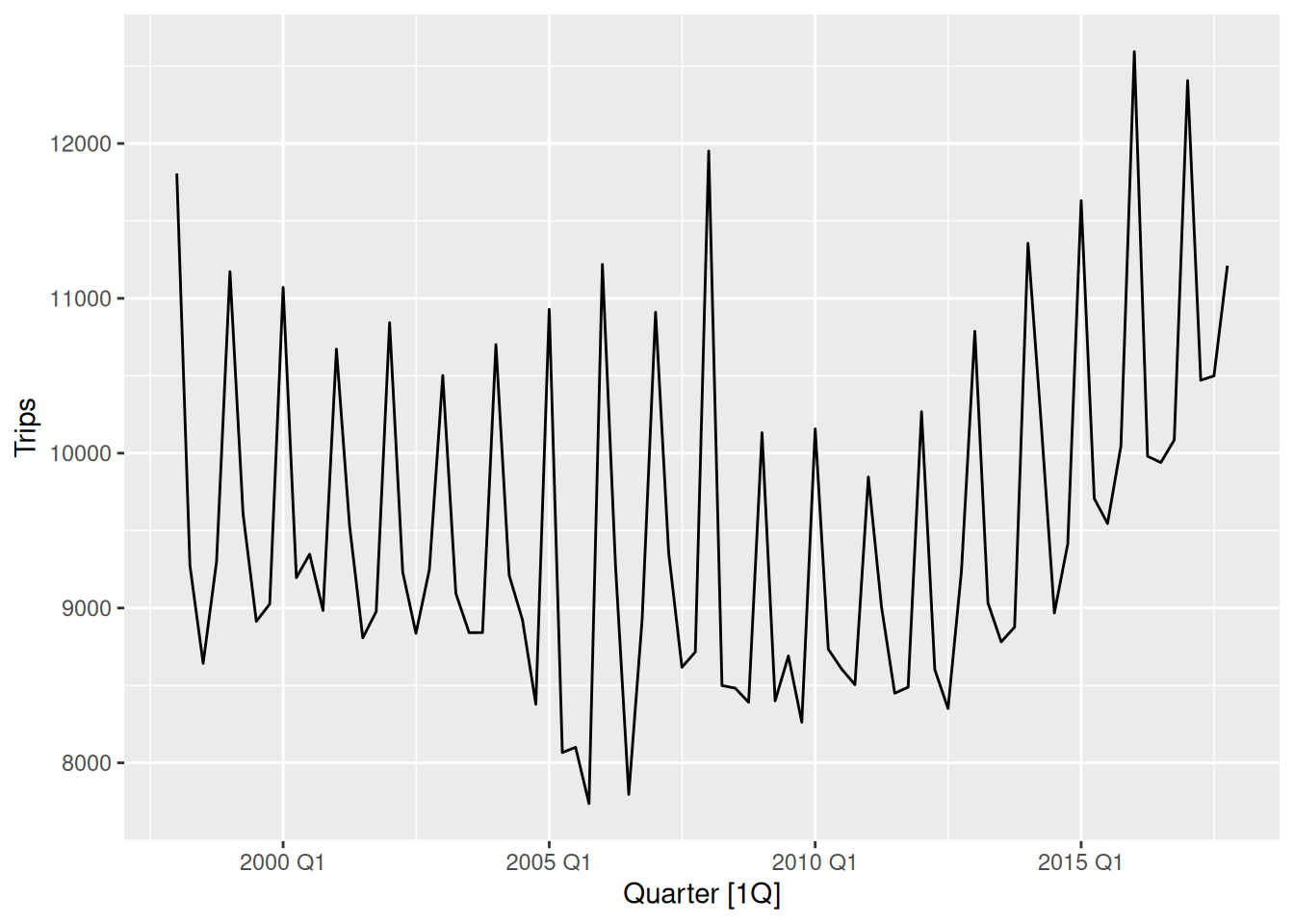
We will forecast the number of holiday trips in Australia using additive and multiplicative Holt-Winters methods.
aus_holidays <- tourism |>
filter(Purpose == "Holiday") |>
summarise(Trips = sum(Trips))
aus_holidays |>
autoplot(Trips)error("A") and season("A") to indicate that we want an additive Holt-Winters model. We will usually set the error() according to the season() type.
error("M") and season("M") to indicate that we want a multiplicative Holt-Winters model. Both models will estimate the smoothing parameters \alpha, \beta^*, and \gamma automatically.
aus_fit <- aus_holidays |>
model(
1 Additive = ETS(Trips ~ error("A") + trend("A") + season("A")),
2 Multiplicative = ETS(Trips ~ error("M") + trend("A") + season("M"))
)
aus_fc <- aus_fit |>
forecast(h = "3 years")
aus_fc |>
autoplot(aus_holidays, level = NULL) + xlab("Year") +
labs(
title = "Forecasting Australian holiday trips using Holt-Winters",
y = "Overnight trips (millions)",
caption = "Can you spot any differences between both forecasts?"
) +
scale_color_brewer(type = "qual", palette = "Dark2") +
guides(colour = guide_legend(title = "Forecast"))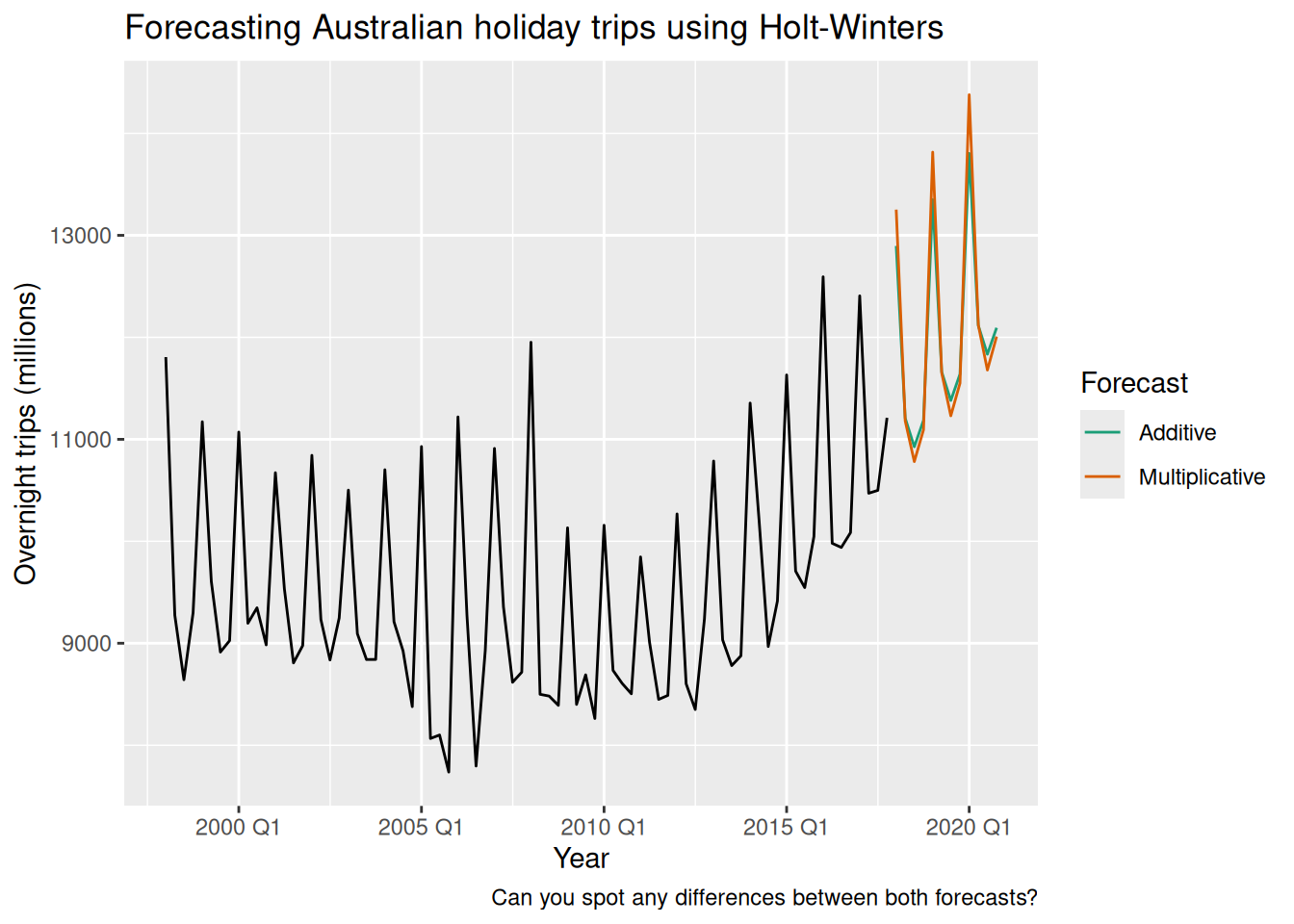
\begin{aligned} \text{Forecast equation} \quad & \hat{y}_{t+h|t} = [\ell_t +(\phi + \phi^2 + \ldots + \phi^h)b_t] s_{t+h-m(k+1)} \\ \text{Level equation} \quad & \ell_t = \alpha \frac{y_t}{s_{t-m}} + (1 - \alpha)(\ell_{t-1} + b_{t-1}) \\ \text{Trend equation} \quad & b_t = \beta^*(\ell_t-\ell_{t-1}) + (1-\beta^*) \phi b_{t-1} \\ \text{Seasonal equation} \quad & s_t = \gamma \frac{y_t}{\ell_{t-1} + \phi b_{t-1}} + (1-\gamma)s_{t-m} \end{aligned}
sth_cross_ped <- pedestrian |>
filter(Date >= "2016-07-01",
Sensor == "Southern Cross Station") |>
index_by(Date) |>
summarise(Count = sum(Count)/1000)
sth_cross_ped |>
filter(Date <= "2016-07-31") |>
model(
hw = ETS(Count ~ error("M") + trend("Ad") + season("M"))
) |>
forecast(h = "2 weeks") |>
autoplot(sth_cross_ped |> filter(Date <= "2016-08-14")) +
labs(title = "Daily traffic: Southern Cross",
y="Pedestrians ('000)")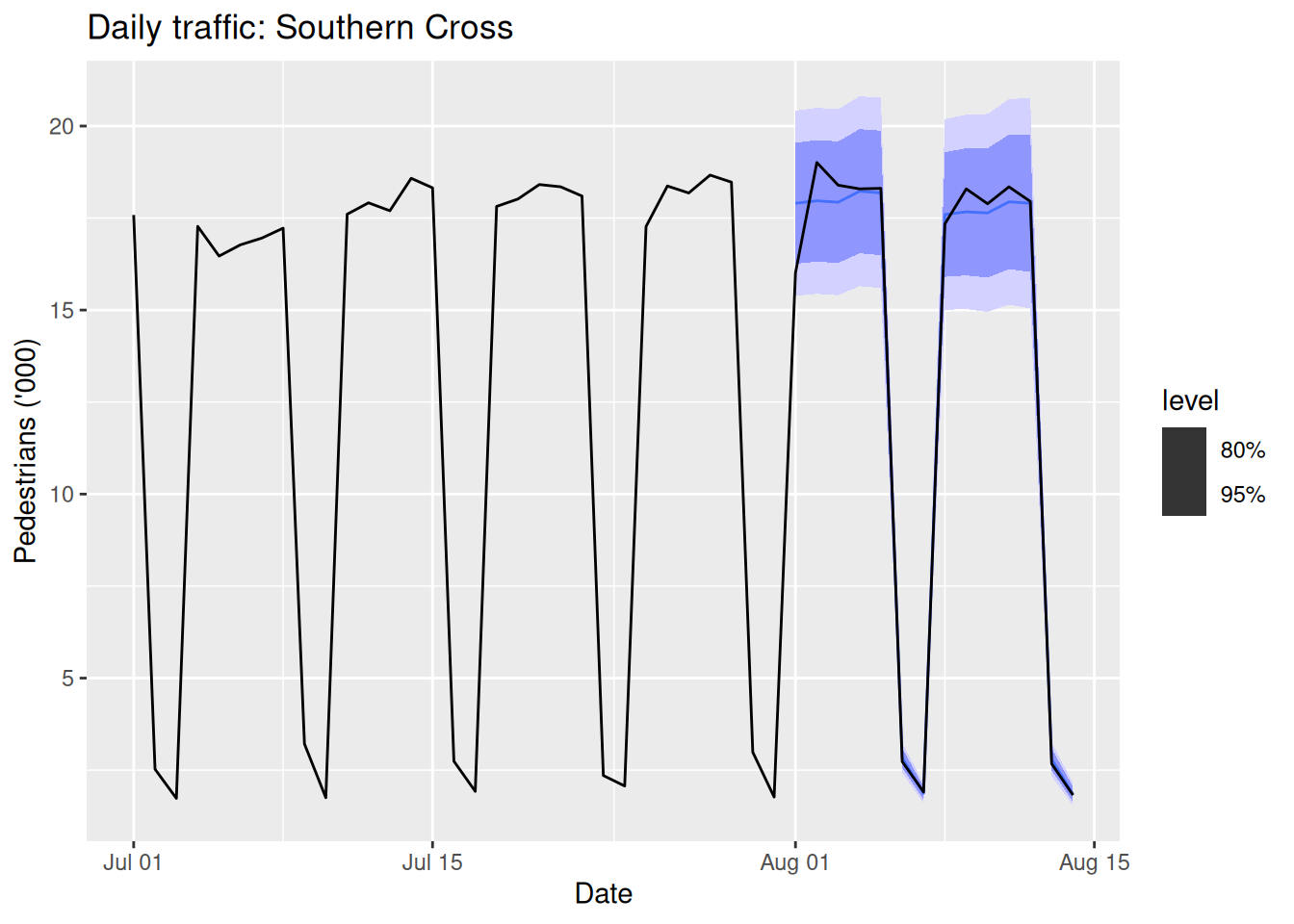
The setup ETS(y ~ error("M") + trend("Ad") + season("M")) is often a robust choice for seasonal data with trend.
fable, we can automatically select the best ETS model for our data using the ETS() function. We achieve this by not specifying the error, trend, or seasonal components.fable to automatically select the best ETS model for each time series.
| Trend component | N (None) | A (Additive) | M (Multiplicative) |
|---|---|---|---|
| N (None) | (N,N), | (N,A) | (N,M) |
| A (Additive) | (A,N), | (A,A) | (A,M) |
| A_d (Additive damped) | (A_d,N), | (A_d, A) | (A_d,M) |
| Notation | Method |
|---|---|
| (N,N) | Simple Exponential Smoothing (SES) |
| (A,N) | Holt’s Linear Trend |
| (A_d,N) | Additive damped Trend |
| (A,A) | Holt-Winters’ Additive |
| (A,M) | Holt-Winters’ Multiplicative |
| (A_d,M) | Holt-Winters’ damped |
error(c("A", "M")), trend(c("N", "A", "Ad")), seasonality(c("N", "A", "M"))) should be based on the characteristics of the data.
(i.e., a mable containing only one model and one time series.)↩︎
In practice, we restrict 0.8 \leq \phi \leq 0.98 because the damping effect would be too great for smaller values than 0.8 and almost non distinguishable from a linear trend for greater values than 0.98.↩︎
e.g., m=4 for quarterly data, m=12 for monthly data, …↩︎
as the decomposition method↩︎
for the seasonally adjusted series↩︎
for the seasonal component↩︎