Exponential smoothing
Example: Forecasting Algeria’s exports
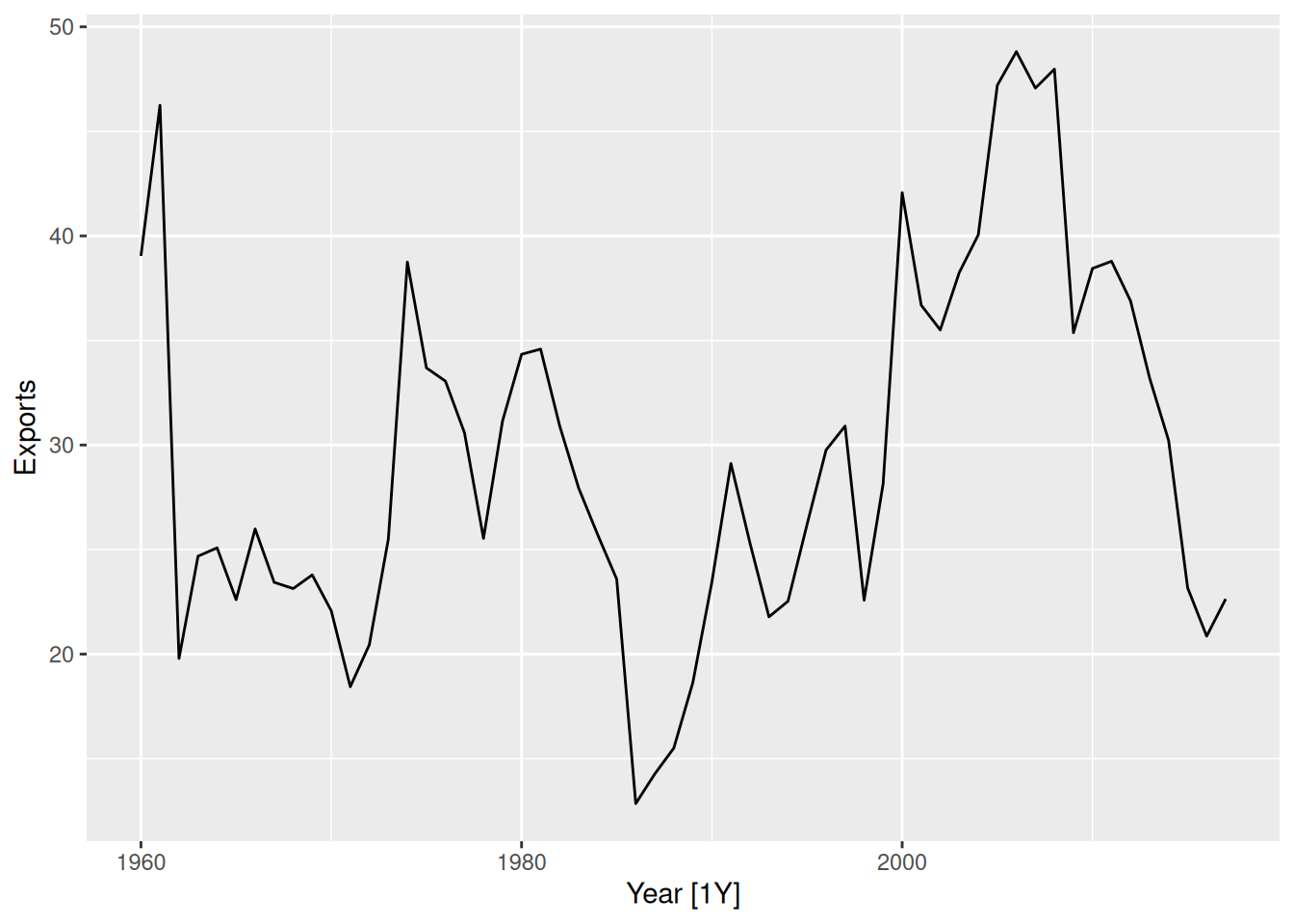
- 1
-
We specify
trend("N")andseason("N")to indicate that we want a simple exponential smoothing (SES) model, which assumes no trend and no seasonality. The model will estimate the smoothing parameter \alpha automatically.
Obtaining the report() of a model
- 1
-
The
report()function allows us to see a model’s report (the time series modeled, the model used, the estimated parameters, and more). It needs a 1 \times 1 dimensionmable1.
Series: Exports
Model: ETS(A,N,N)
Smoothing parameters:
alpha = 0.8399875
Initial states:
l[0]
39.539
sigma^2: 35.6301
AIC AICc BIC
446.7154 447.1599 452.8968 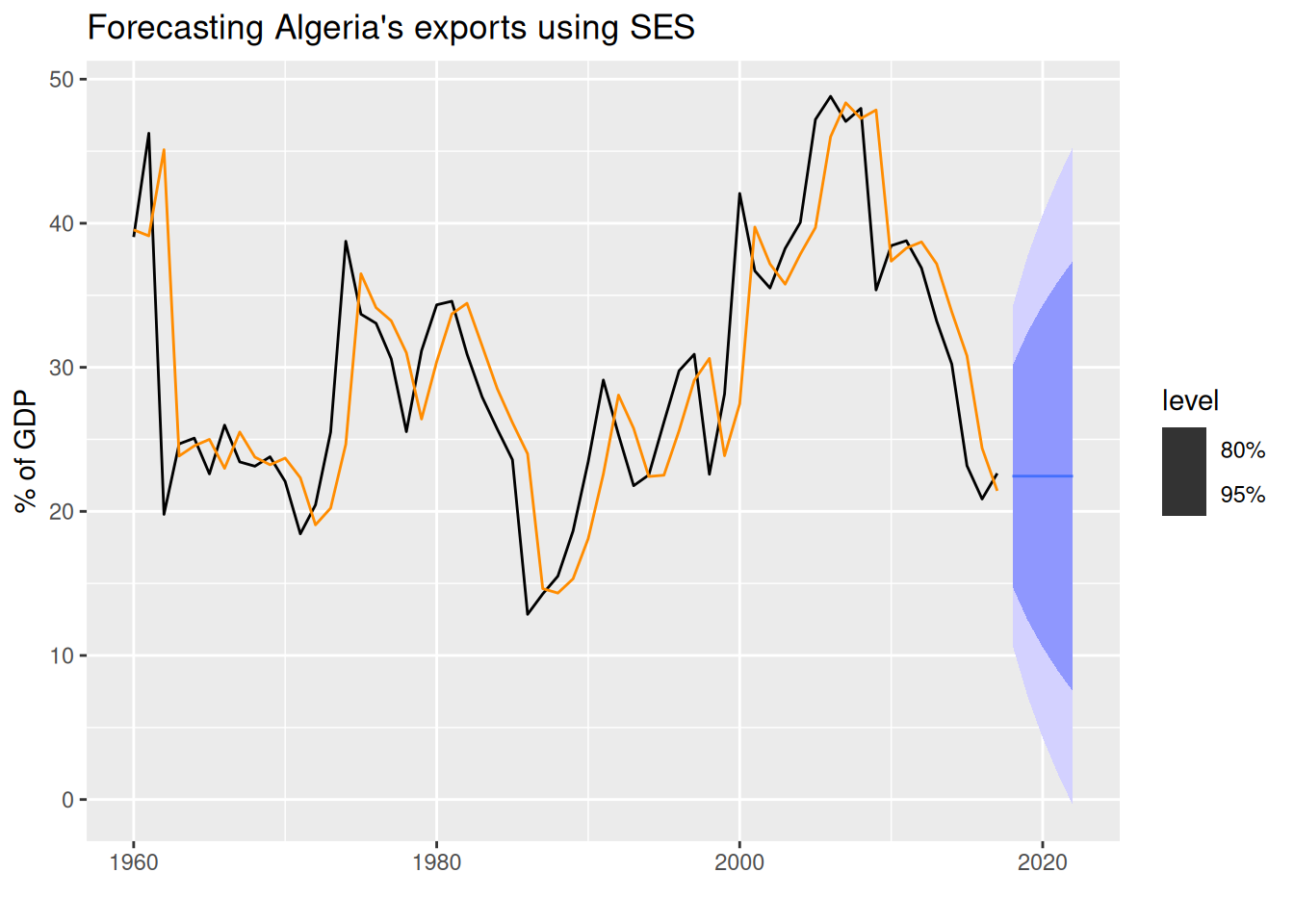
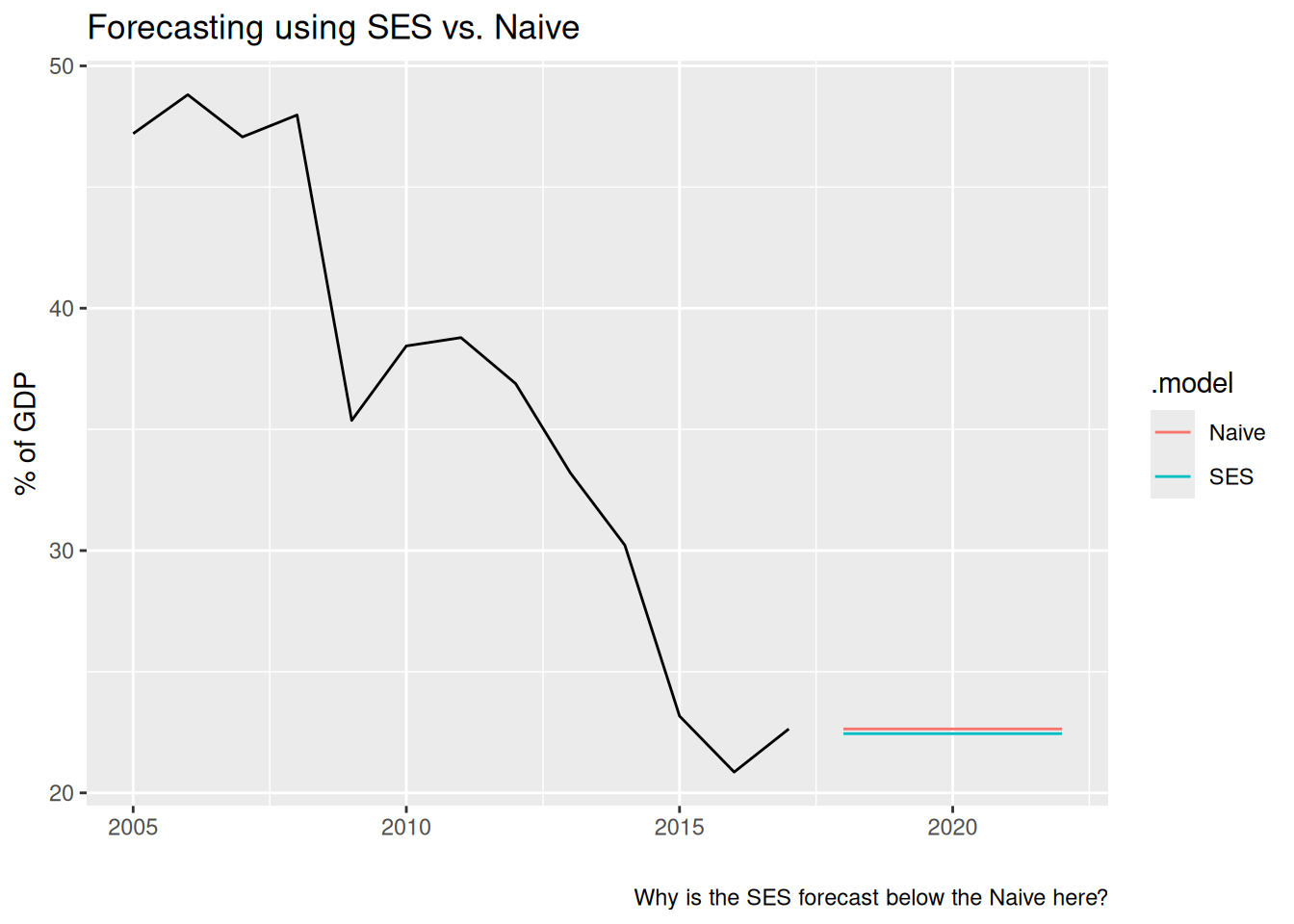
Comparing the SES and Naive forecasts:
Example: Forecasting Brazil’s population
Example: Forecasting Brazil’s population
bra_fit <- bra_economy |>
model(
Holt = ETS(Pop ~ error("A") + trend("A") + season("N")),
Drift = RW(Pop ~ drift())
)
bra_fit |>
select(Holt) |>
report()
bra_fc <- bra_fit |>
forecast(h = 15)
bra_fc |>
autoplot(bra_economy, level = NULL) +
labs(title = "Brazilian population",
y = "Millions") +
guides(colour = guide_legend(title = "Forecast"))- 1
-
We specify
trend("A")to indicate that we want a linear trend. The model will estimate the smoothing parameters \alpha and \beta^* automatically.
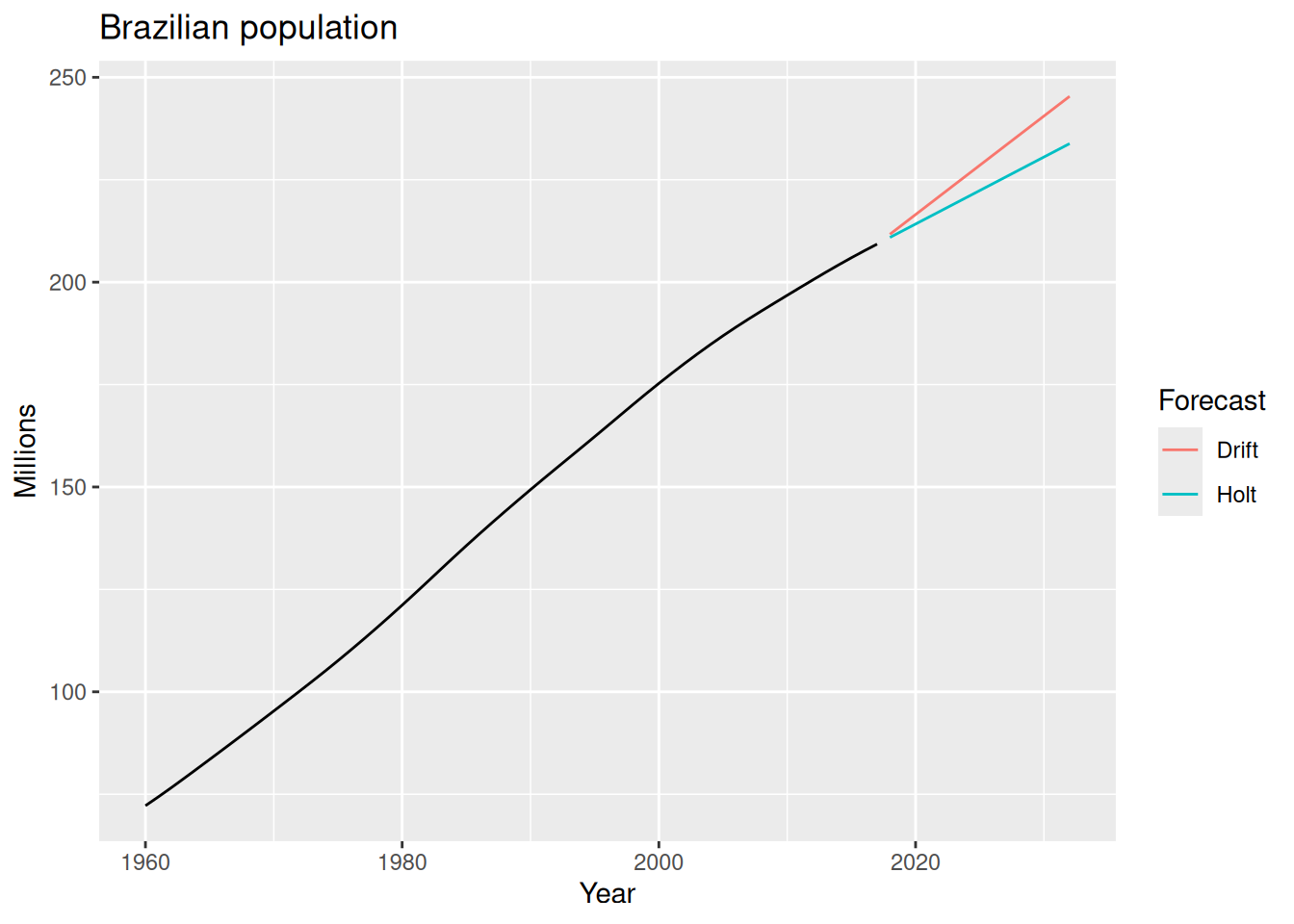
Series: Pop
Model: ETS(A,A,N)
Smoothing parameters:
alpha = 0.9999
beta = 0.9998999
Initial states:
l[0] b[0]
70.06297 2.132884
sigma^2: 0.0021
AIC AICc BIC
-115.2553 -114.1014 -104.9531 Example: Forecasting Brazil’s population (continued)
bra_economy |>
model(
Holt = ETS(Pop ~ error("A") + trend("A") + season("N")),
Damped = ETS(Pop ~ error("A") + trend("Ad", phi = 0.9) + season("N"))
) |>
forecast(h = 15) |>
autoplot(bra_economy, level = NULL) +
labs(title = "Brazilian population",
y = "Millions") +
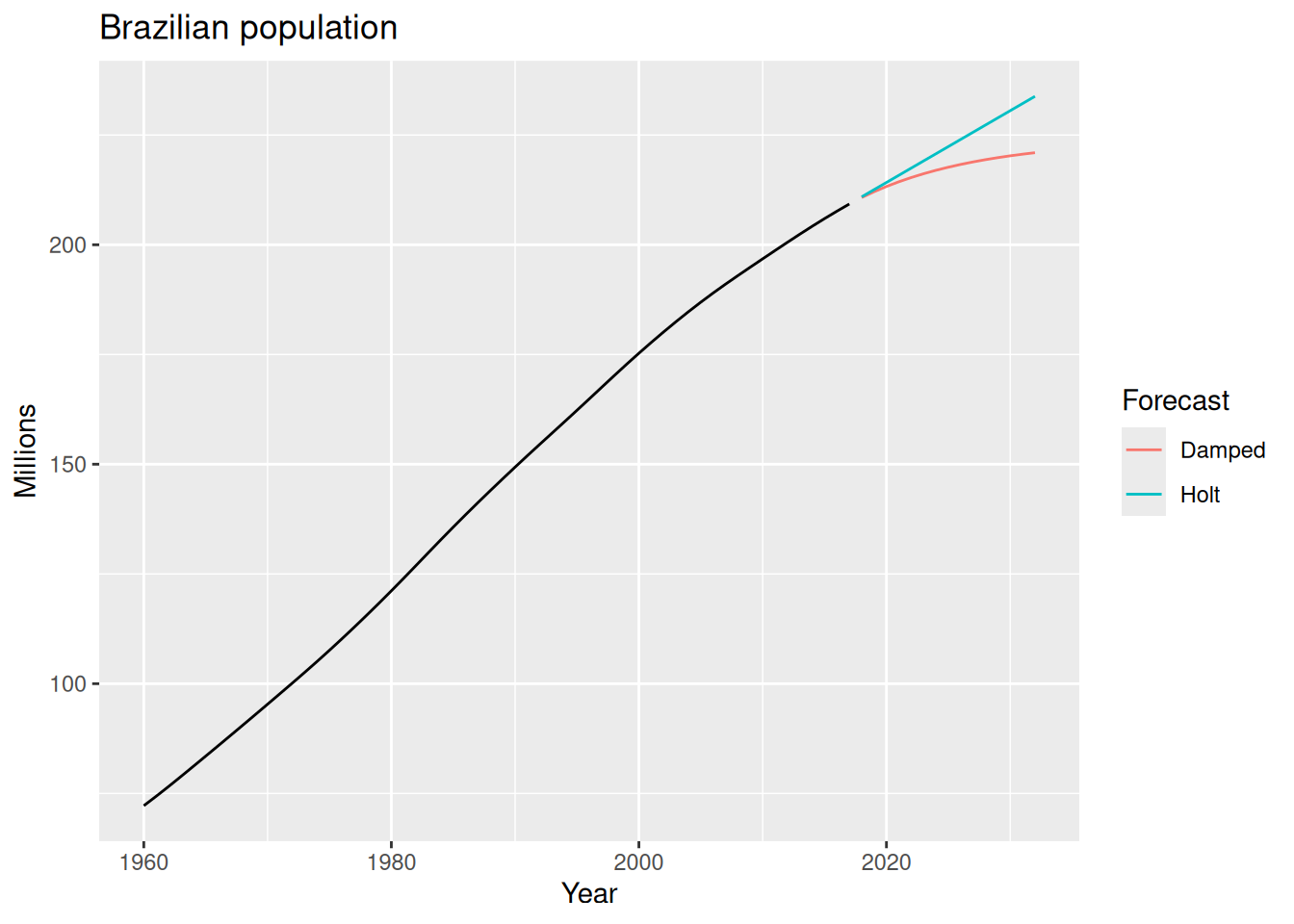
guides(colour = guide_legend(title = "Forecast"))- 1
-
We specify
trend("Ad")to indicate that we want a damped trend, andphi = 0.9sets the damping parameter to 0.9. We could also let the model estimate \phi automatically by omitting thephiargument.
Example: Forecasting Australian holiday trips
Example: Forecasting Australian holiday trips
aus_fc |>
autoplot(aus_holidays, level = NULL) + xlab("Year") +
labs(
title = "Forecasting Australian holiday trips using Holt-Winters",
y = "Overnight trips (millions)",
caption = "Can you spot any differences between both forecasts?"
) +
scale_color_brewer(type = "qual", palette = "Dark2") +
guides(colour = guide_legend(title = "Forecast"))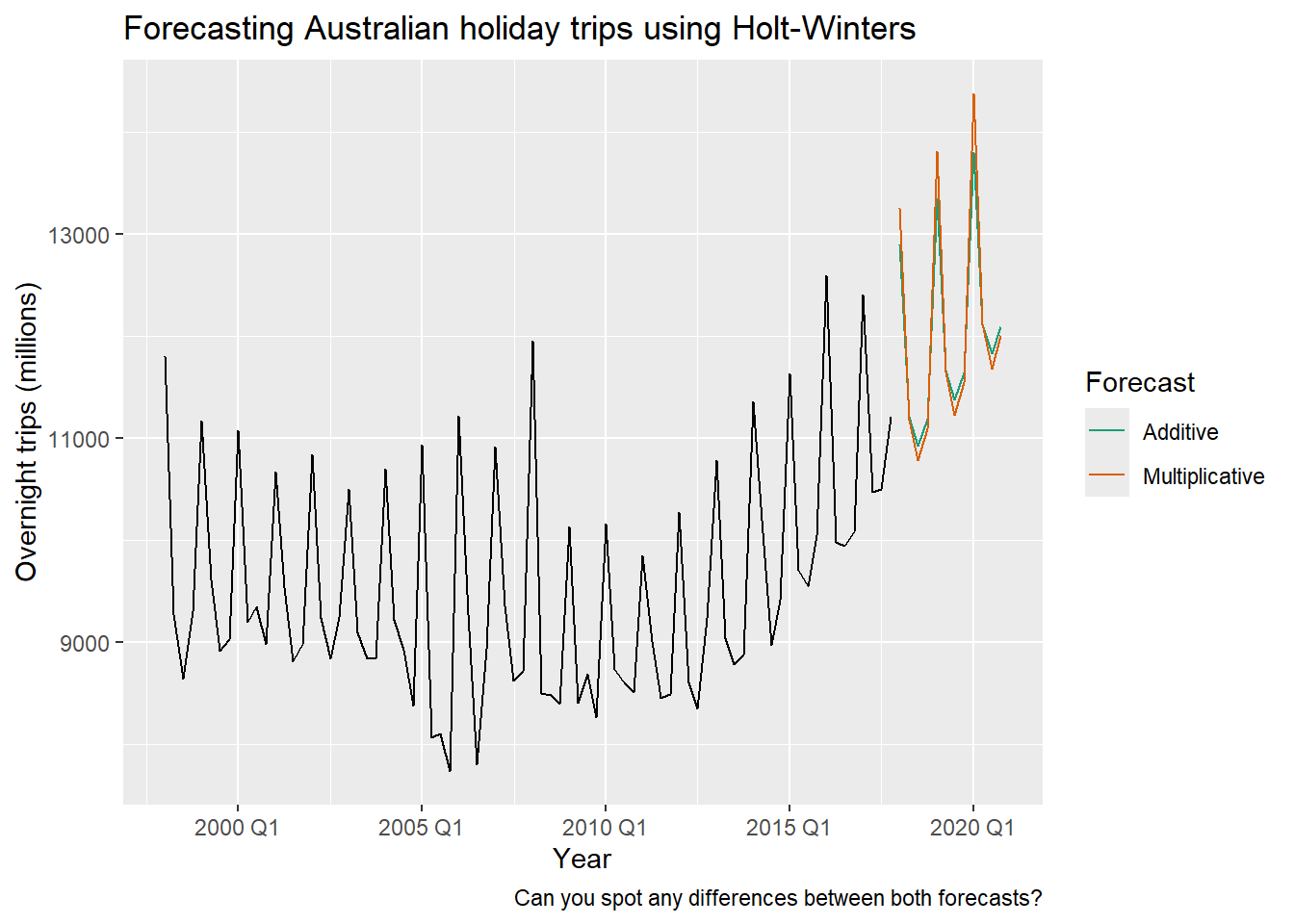
Example: Forecasting daily pedestrian traffic
sth_cross_ped <- pedestrian |>
filter(Date >= "2016-07-01",
Sensor == "Southern Cross Station") |>
index_by(Date) |>
summarise(Count = sum(Count)/1000)
sth_cross_ped |>
filter(Date <= "2016-07-31") |>
model(
hw = ETS(Count ~ error("M") + trend("Ad") + season("M"))
) |>
forecast(h = "2 weeks") |>
autoplot(sth_cross_ped |> filter(Date <= "2016-08-14")) +
labs(title = "Daily traffic: Southern Cross",
y="Pedestrians ('000)")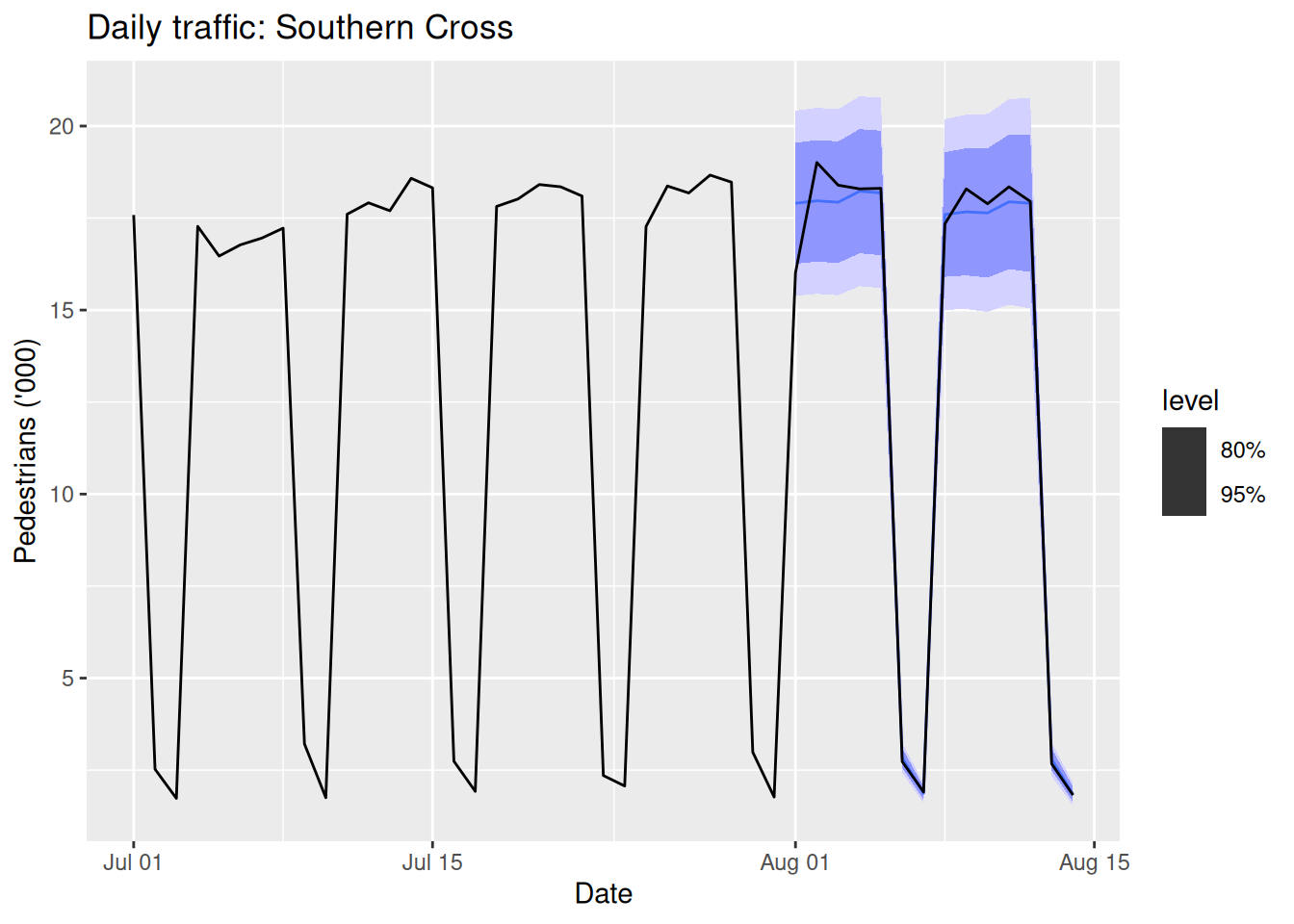
The setup ETS(y ~ error("M") + trend("Ad") + season("M")) is often a robust choice for seasonal data with trend.
Footnotes
(i.e., a
mablecontaining only one model and one time series.)In practice, we restrict 0.8 \leq \phi \leq 0.98 because the damping effect would be too great for smaller values than 0.8 and almost non distinguishable from a linear trend for greater values than 0.98.
e.g., m=4 for quarterly data, m=12 for monthly data, …
as the decomposition method
for the seasonally adjusted series
for the seasonal component