Modular Forecasting: Mixing ETS and ARIMA
Forecasts
Setup
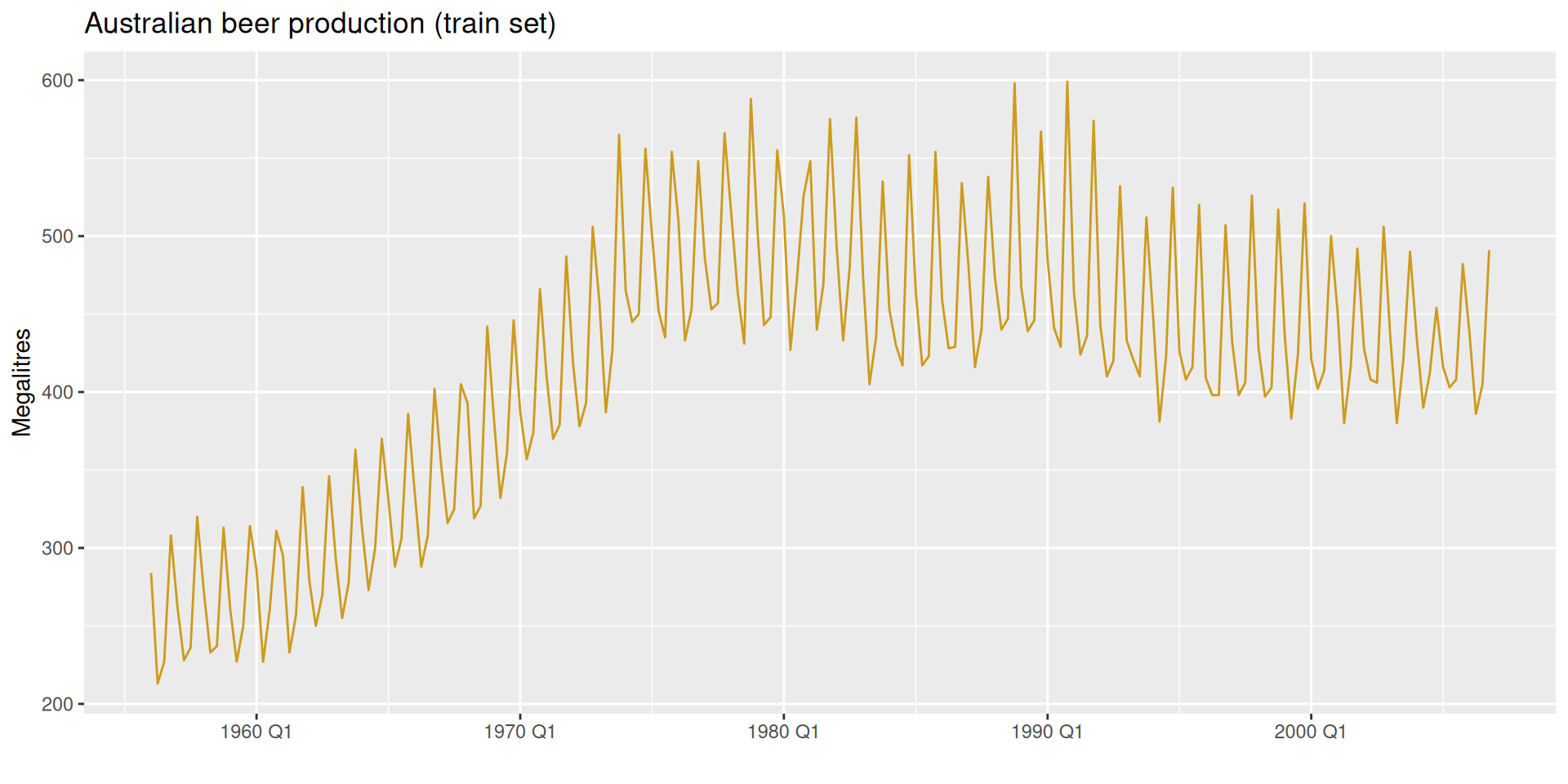
To check whether the rankings hold on a different series, we apply the same workflow to quarterly Australian beer production from fpp3:
- 1
-
We rename
Beertoy— the same convention used formexretail. This is what allows the specs defined above to be reused directly.
Reusing model specs across series
Because both mexretail and beer use log(y) as the response variable, the specs defined above apply to both series without any modification. The mable for beer will look identical to the one for mexretail — the only difference is the tsibble being piped in.
This is the payoff of two conventions working together: naming your response variable y, and defining specs outside the mable.
Forecasts and accuracy
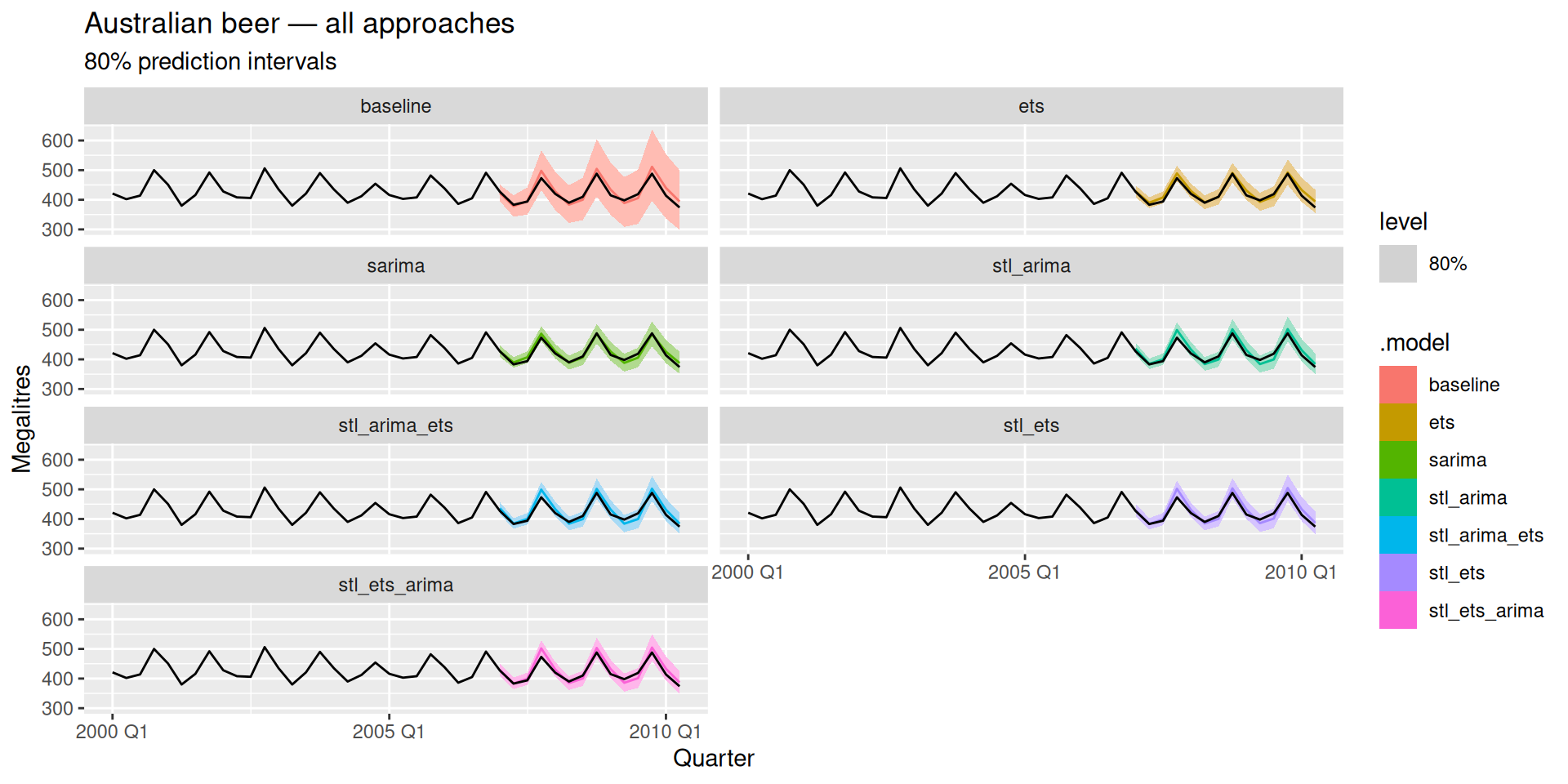
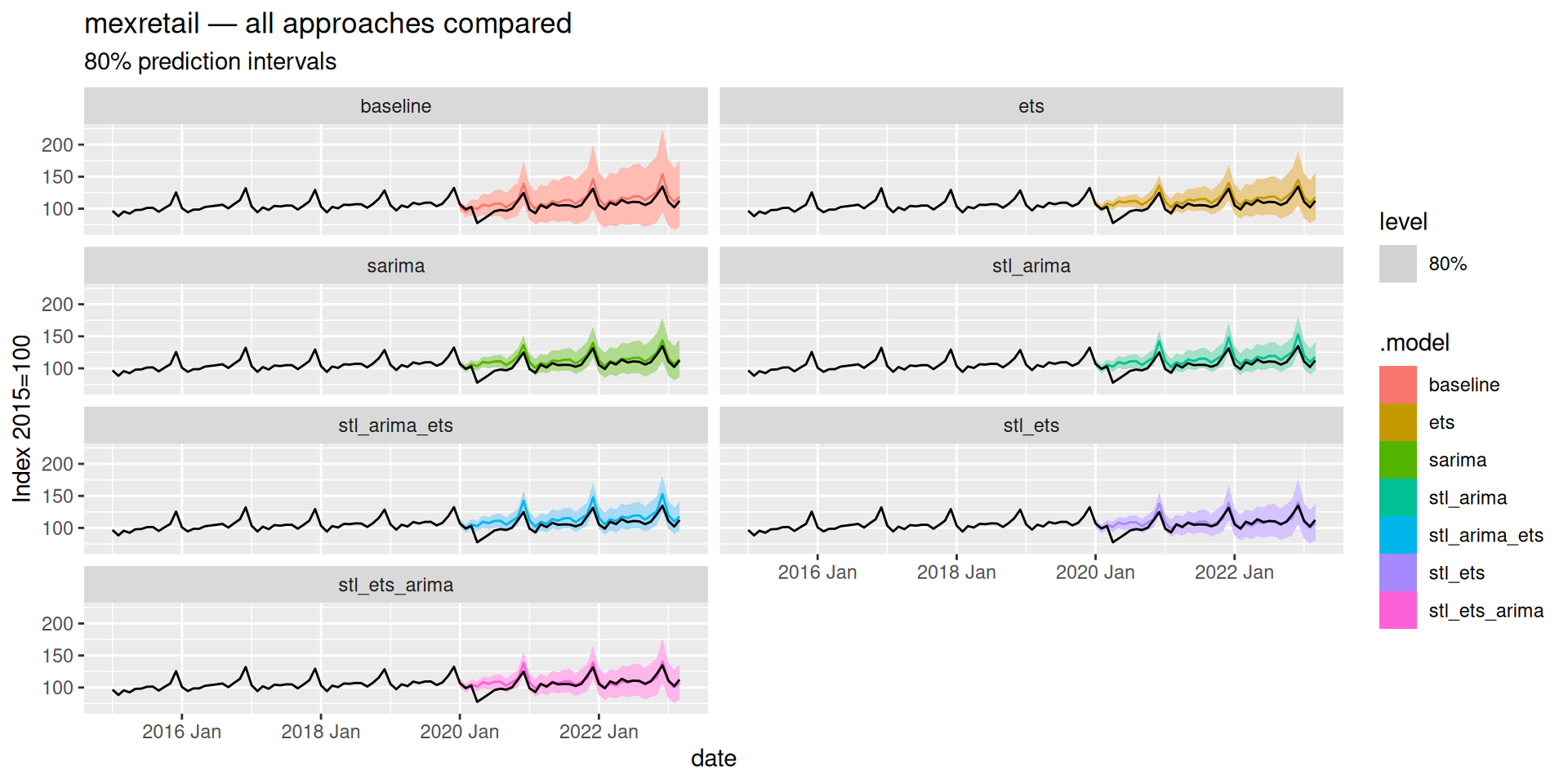
Does the winner change?
Compare the ranking here against mexretail. Does the same approach win on both series? What does that tell you about when mixed decomposition models add value — and when they don’t?