graph TD
MX["Mexico (Total)"]
OAX["Oaxaca"]
JAL["Jalisco"]
ETC["···"]
OJ["Oaxaca City"]
MH["Miahuatlán"]
GDL["Guadalajara"]
TQ["Tequila"]
MX --> OAX
MX --> JAL
MX --> ETC
OAX --> OJ
OAX --> MH
JAL --> GDL
JAL --> TQ
Hierarchical & Grouped Forecasting
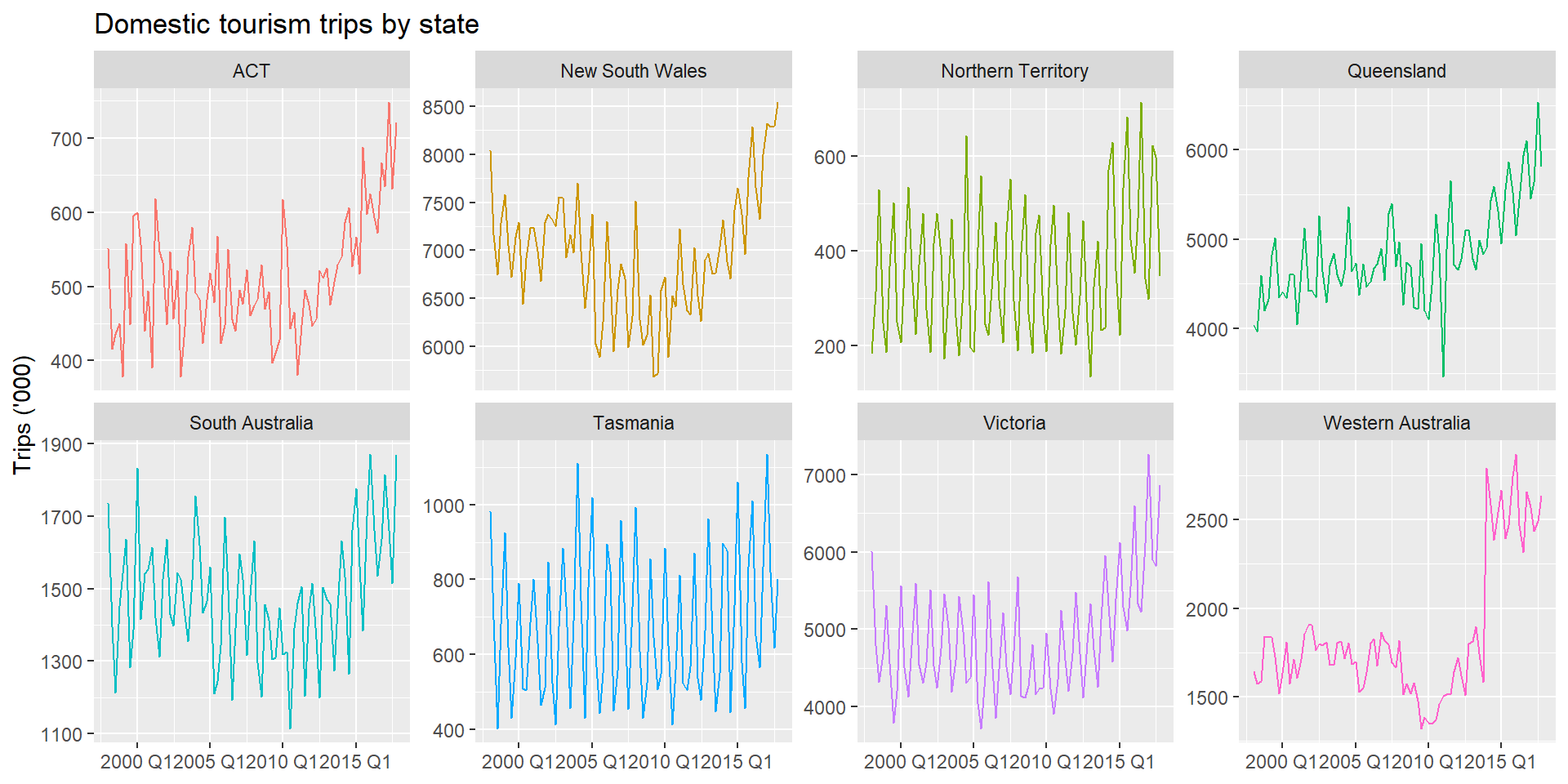
Visualizing Aggregated Series
autoplot() on an aggregated tsibble works as usual. Use filter() with is_aggregated() to select a specific level.
Mixed Structure: Hierarchy + Grouping
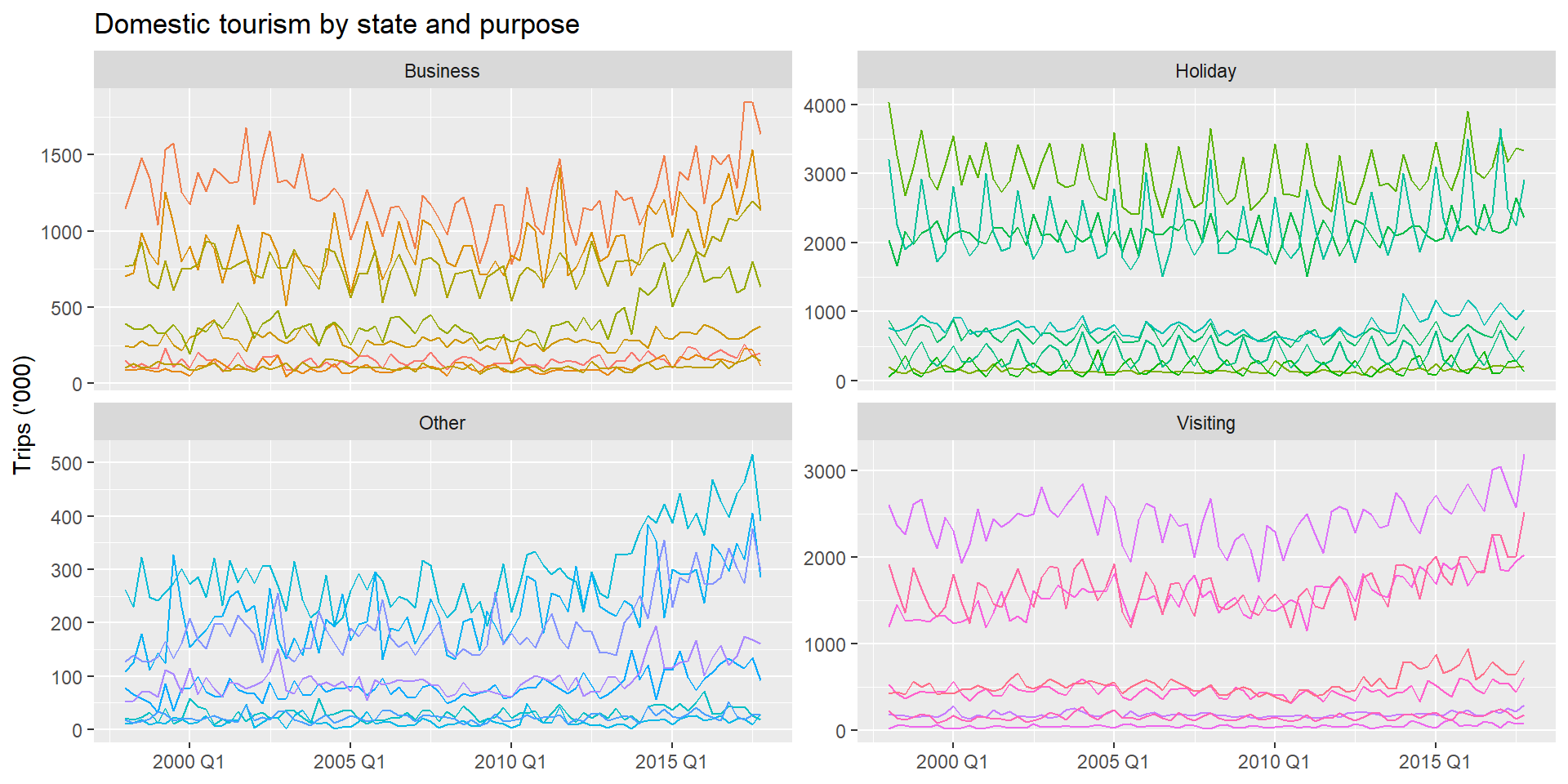
With tourism_full, the Purpose grouping is crossed with the State/Region hierarchy:
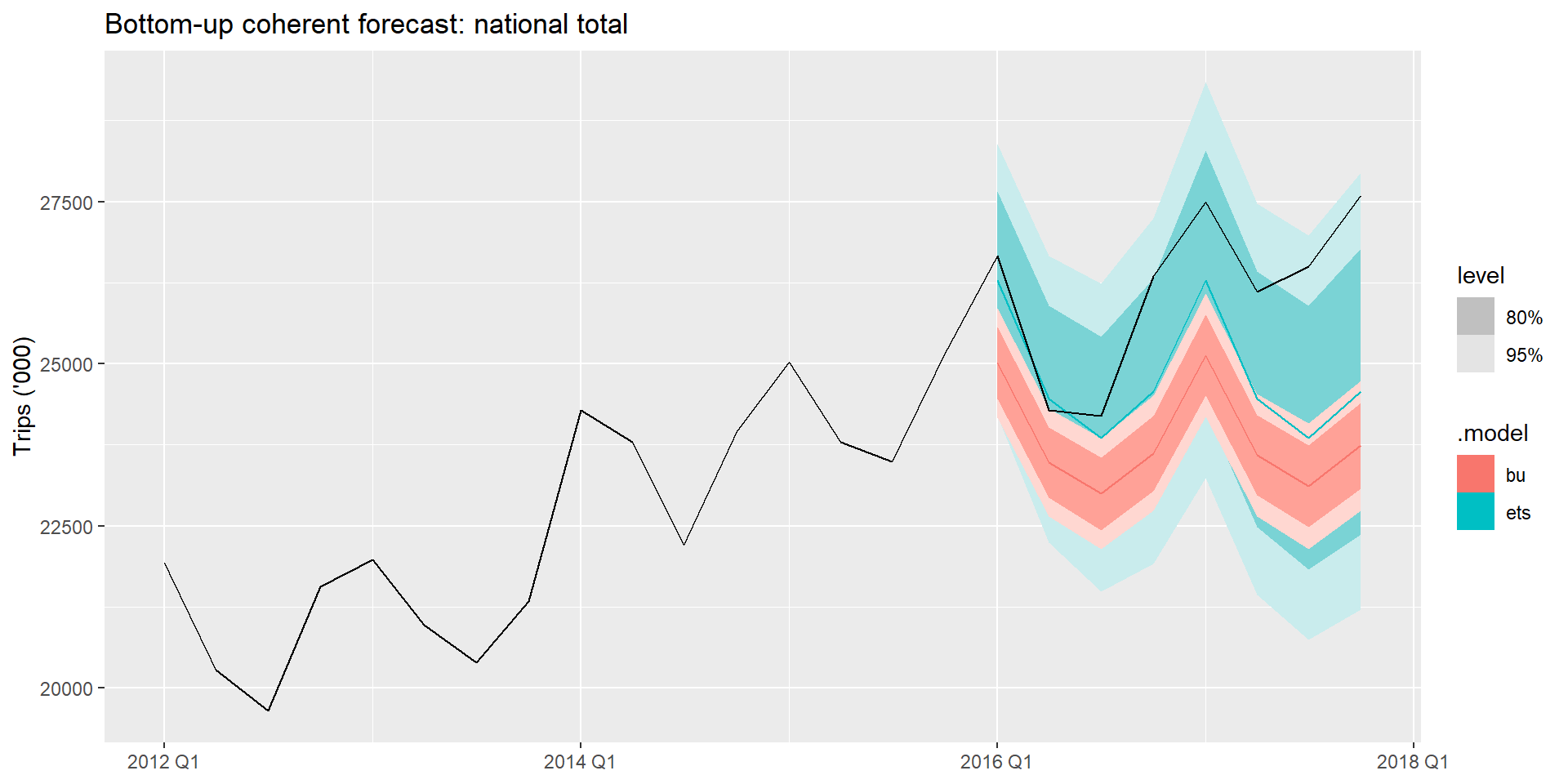
Bottom-Up
Forecast the most disaggregated series, then aggregate up.
- 1
-
bottom_up(ets)takes the Region-level ETS forecasts as given and sums up. The national and state ETS forecasts are replaced by aggregations of the Region forecasts.
Accuracy by Level
tourism_fc |>
accuracy(data = tourism_hts, measures = list(RMSSE = RMSSE)) |>
mutate(
Level = case_when(
is_aggregated(State) ~ "Total",
!is_aggregated(State) & is_aggregated(Region) ~ "State",
TRUE ~ "Region"
)
) |>
group_by(.model, Level) |>
summarise(RMSSE = mean(RMSSE, na.rm = TRUE), .groups = "drop") |>
mutate(Level = factor(Level, levels = c("Total", "State", "Region")),
.model = fct_reorder(.model, RMSSE)) |>
ggplot(aes(x = .model, y = RMSSE, fill = .model)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ Level, scales = "free_y") +
coord_flip() +
labs(x = NULL, y = "Mean RMSSE") +
theme_minimal()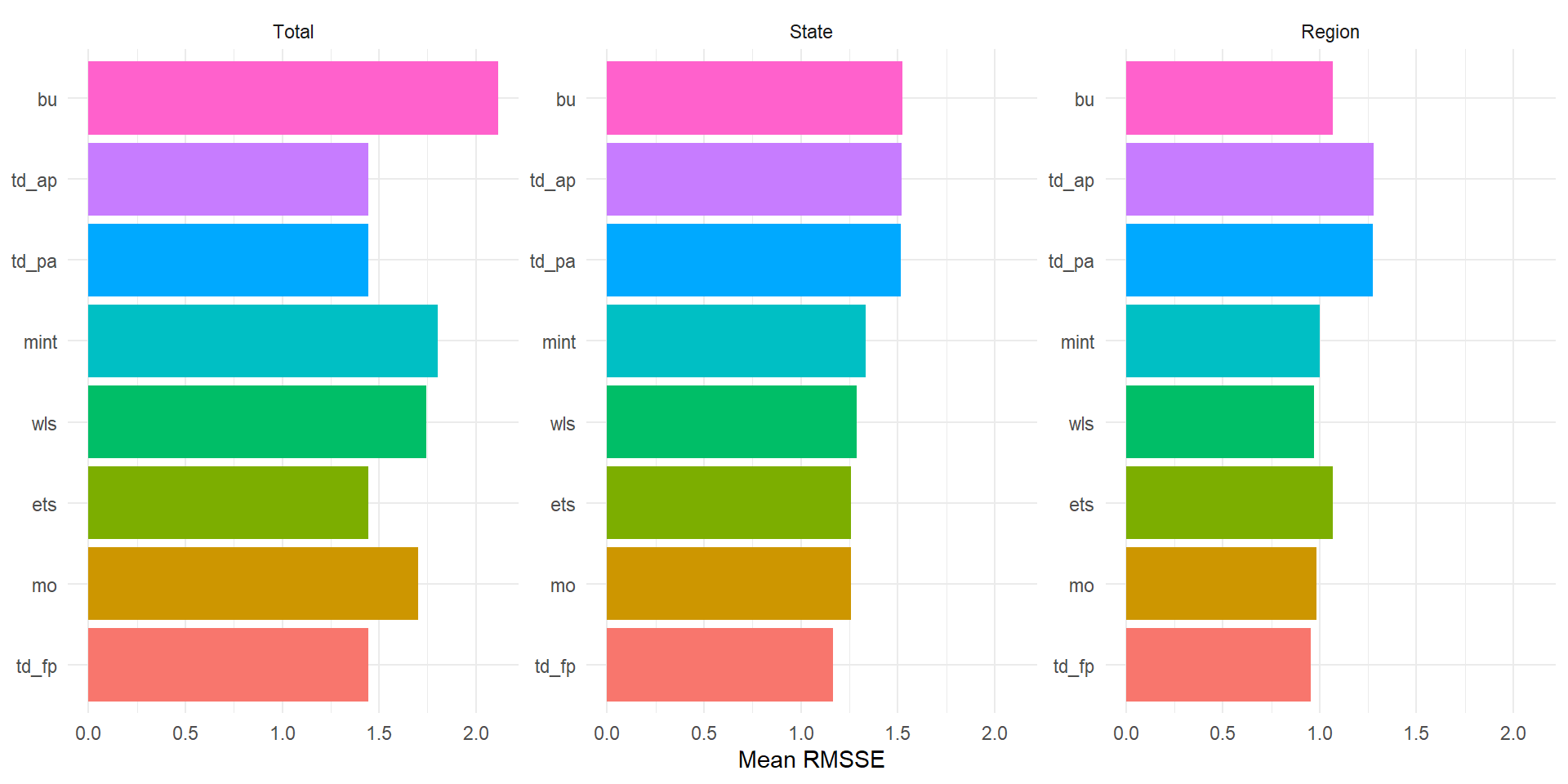
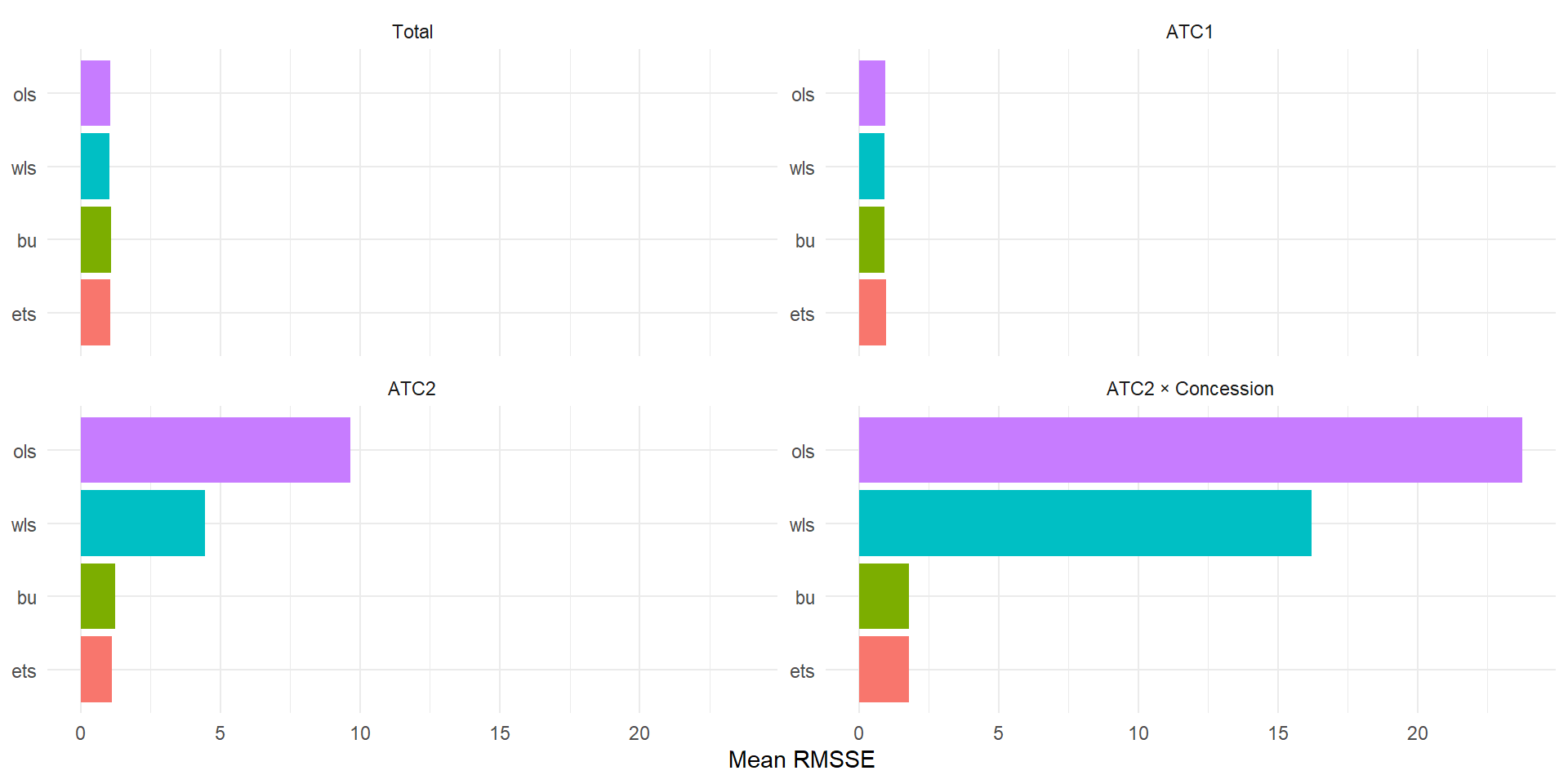
Reading the chart
Single-level methods tend to perform best at their “home” level (BU at Region, TD at Total) and worse elsewhere. MinT shrink typically does well across all levels because it does not privilege any single level.
PBS: Accuracy
pbs_fc |>
accuracy(data = pbs_hts, measures = list(RMSSE = RMSSE)) |>
mutate(
Level = case_when(
is_aggregated(ATC1) ~ "Total",
!is_aggregated(ATC1) & is_aggregated(ATC2) & is_aggregated(Concession) ~ "ATC1",
!is_aggregated(ATC2) & is_aggregated(Concession) ~ "ATC2",
TRUE ~ "ATC2 × Concession"
)
) |>
group_by(.model, Level) |>
summarise(RMSSE = mean(RMSSE, na.rm = TRUE), .groups = "drop") |>
mutate(
Level = factor(Level, levels = c("Total", "ATC1", "ATC2", "ATC2 × Concession")),
.model = fct_reorder(.model, RMSSE)
) |>
ggplot(aes(x = .model, y = RMSSE, fill = .model)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ Level, scales = "free_y") +
coord_flip() +
labs(x = NULL, y = "Mean RMSSE") +
theme_minimal()