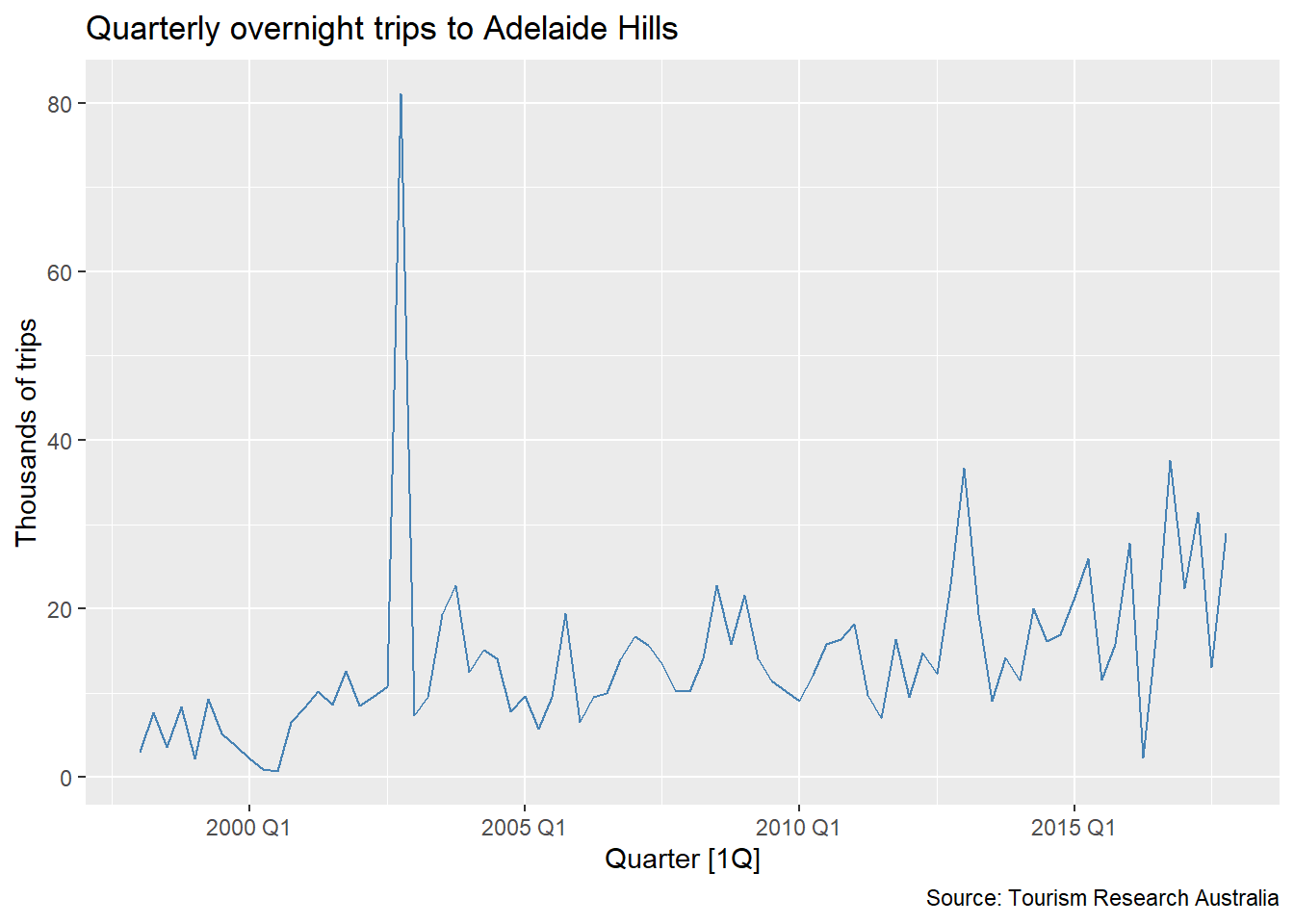
Practical Forecasting Issues
Formally identifying outliers via STL
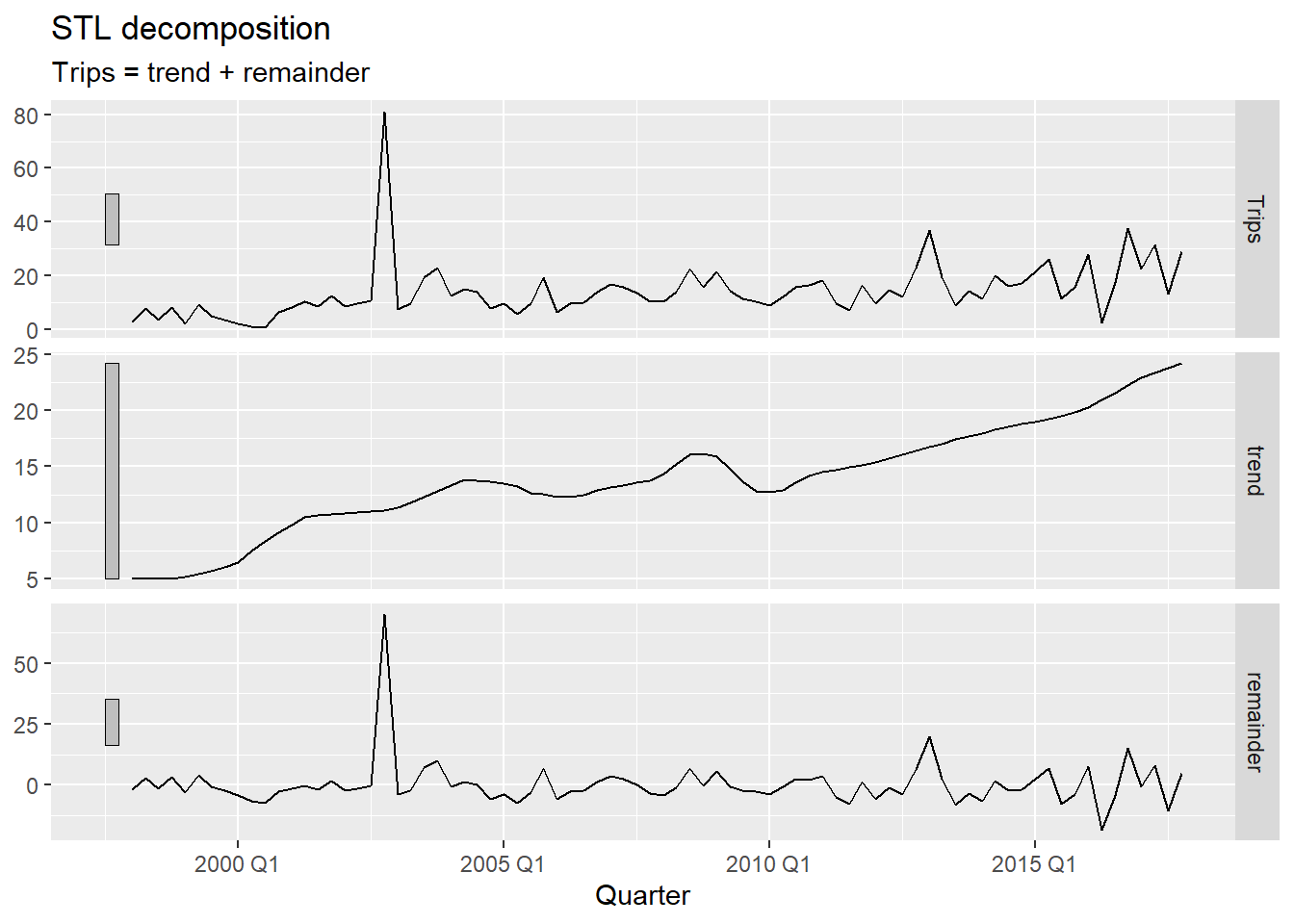
We decompose the series with STL using season(period = 1) to remove only the trend — keeping seasonality in the remainder so it is not mistaken for an anomaly1. We then apply the IQR rule to the remainder:
\text{outlier if } R_t < Q_1 - c \cdot \text{IQR} \quad \text{or} \quad R_t > Q_3 + c \cdot \text{IQR}
where c = 1.5 is the standard threshold and c = 3 flags only more extreme observations.
- 1
-
season(period = 1)fits a non-seasonal STL — only the trend is extracted. This ensures the remainder reflects true anomalies and seasonal variation together, rather than having a genuine outlier absorbed into the seasonal component.
- 1
-
Changing
c_thresholdto3makes detection stricter — only more extreme remainders are flagged. Start with1.5and increase if too many periods are flagged.
Choosing the threshold: 1.5 vs. 3
The value c = 1.5 is the standard Tukey fence used in boxplots — it flags observations that are moderately unusual. A value of c = 3 (the “far fence”) is more conservative and only captures truly extreme values. In practice, start with 1.5, inspect the flagged periods, and tighten the threshold if normal variation is being flagged.
The problem
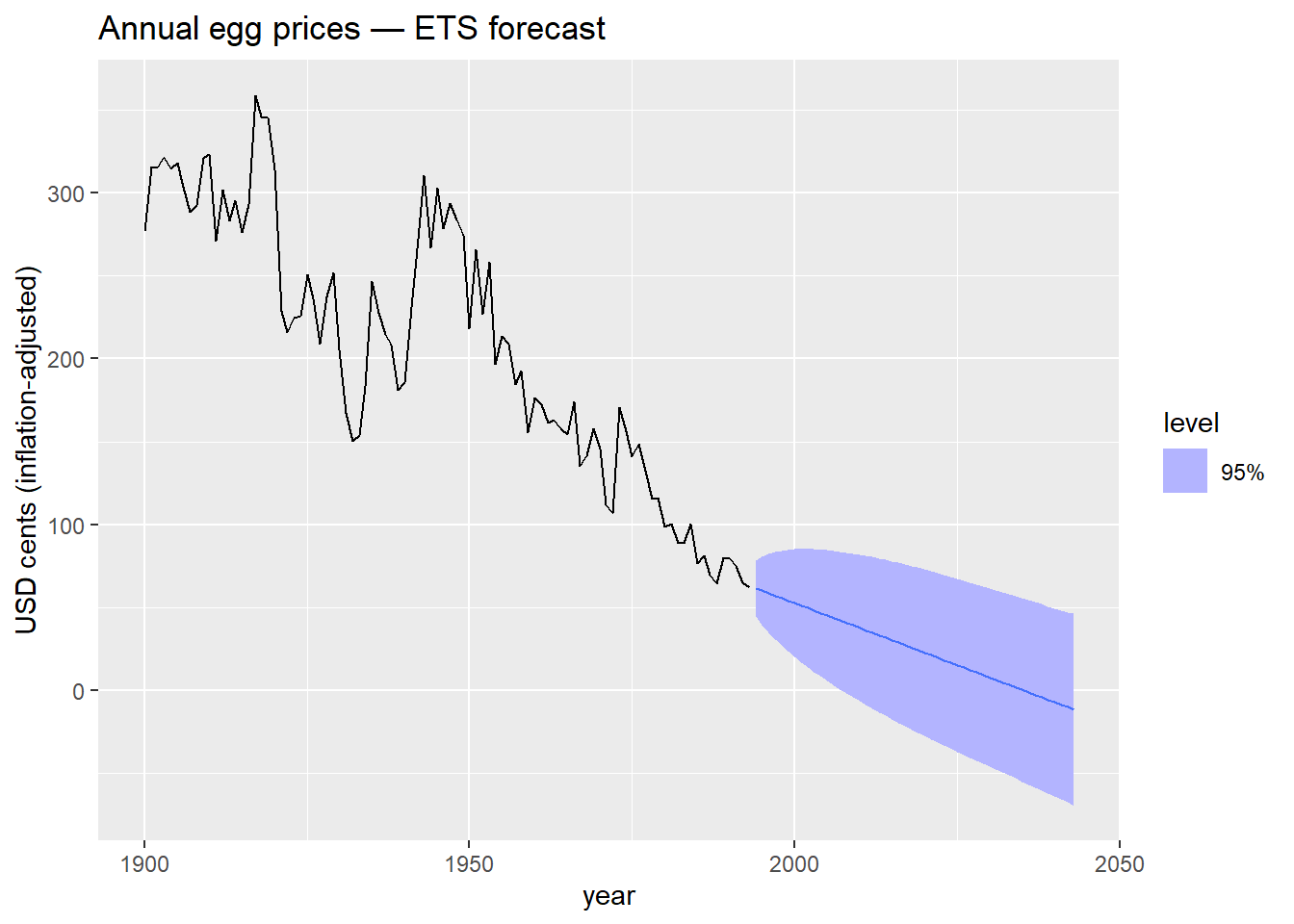
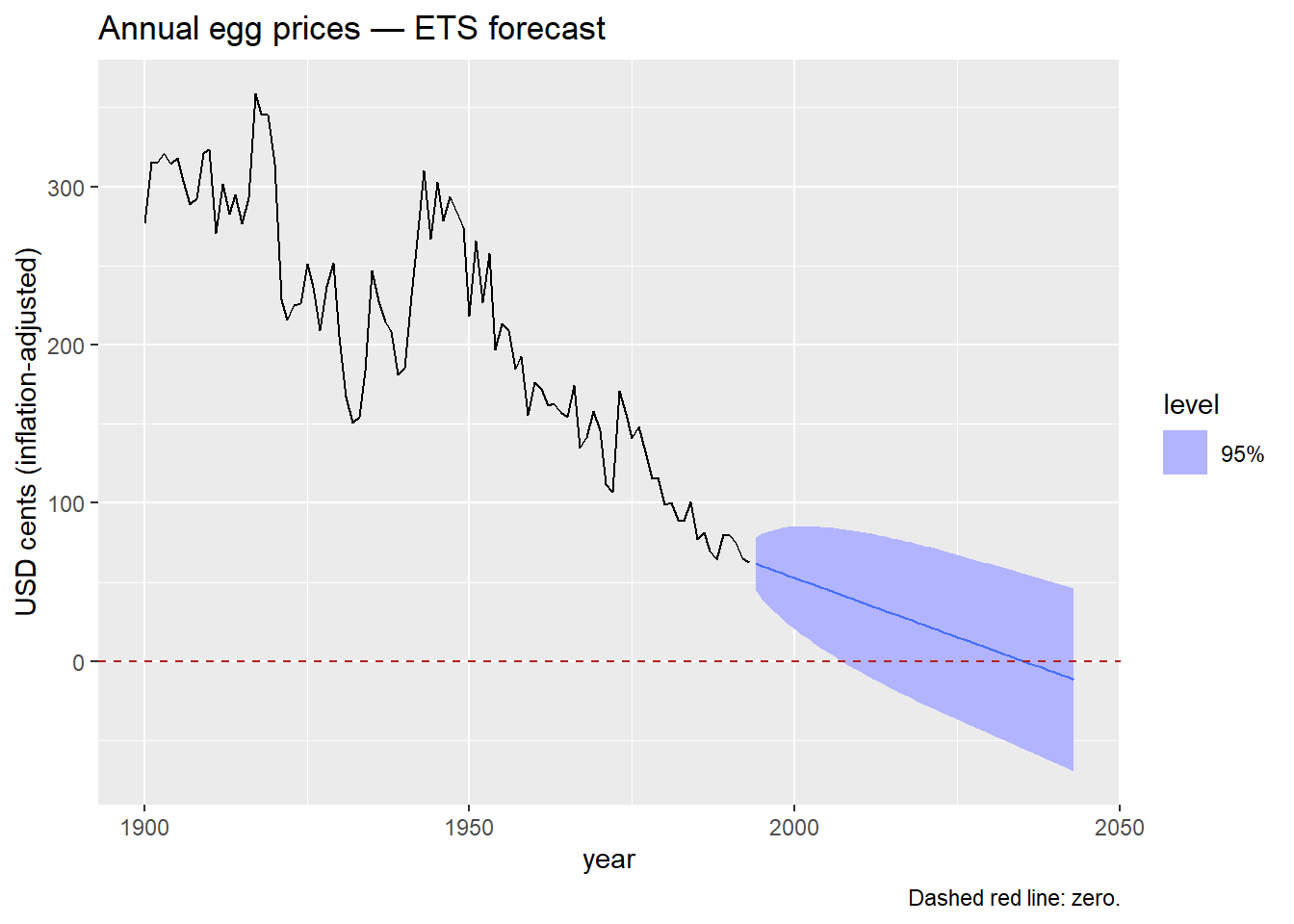
What do you observe? Does anything look strange about those prediction intervals?
The log transformation
- \log(y_t) is defined only for y_t > 0, and \log(y_t) \to -\infty as y_t \to 0^+.
- When we model \log(y_t) and back-transform with \exp(\cdot), the result is always strictly positive — regardless of how far the trend extrapolates downward.
- We saw this in Module 1 with Box-Cox transformations (the \lambda = 0 case). Here we use it explicitly as a forecasting constraint.
- 1
-
The only change is wrapping
eggsinlog().fablehandles the back-transformation automatically — forecasts and prediction intervals are returned on the original scale.
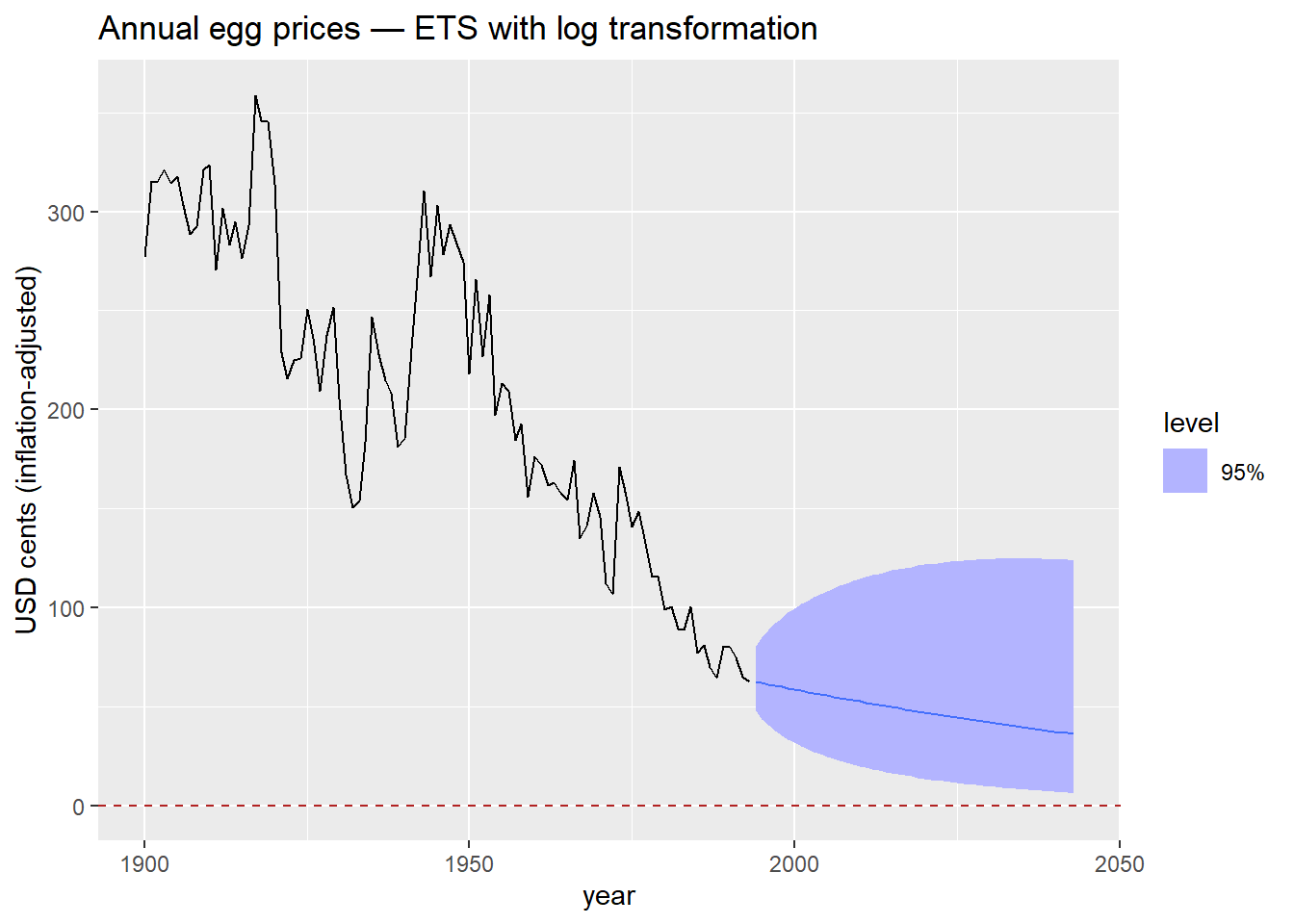
The log transformation is the simplest way to keep forecasts positive. It works well when the series is strictly positive and the variance grows with the level — both common features of price and volume data.
Applying the scaled logit
egg_prices |>
model(
ETS(my_scaled_logit(eggs, lower = 50, upper = 400) ~ trend("A"))
) |>
forecast(h = 50) |>
autoplot(egg_prices, level = 95) +
geom_hline(yintercept = 50, color = "firebrick", linetype = "dashed") +
geom_hline(yintercept = 400, color = "firebrick", linetype = "dashed") +
labs(
title = "Annual egg prices — ETS within bounds [50, 400]",
y = "USD cents (inflation-adjusted)",
caption = "Dashed red lines: lower bound (50) and upper bound (400)."
)- 1
-
The bounds
lower = 50andupper = 400reflect a plausible range for egg prices in this dataset. In practice, bounds should be informed by domain knowledge or regulatory constraints — not chosen to make the plot look neat.
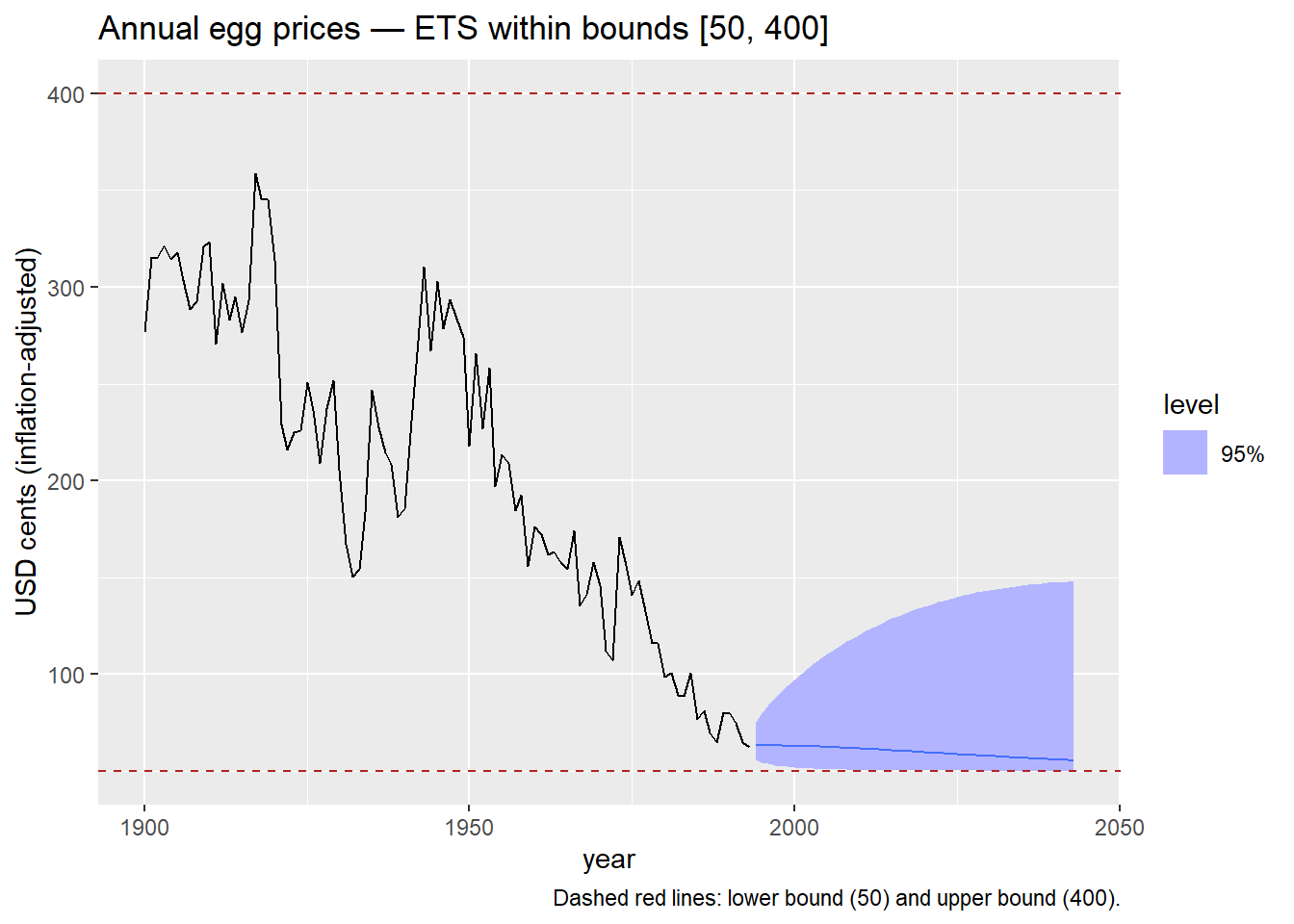
The scaled logit requires that all historical observations fall strictly within (a, b). If any observation equals or exceeds the bounds, the transformation is undefined. Always verify your data range before applying it.
Footnotes
If you suspect outliers are hiding inside the seasonal pattern, you can use a full seasonal decomposition instead.