Forecasting Foundations
A tidy forecasting workflow
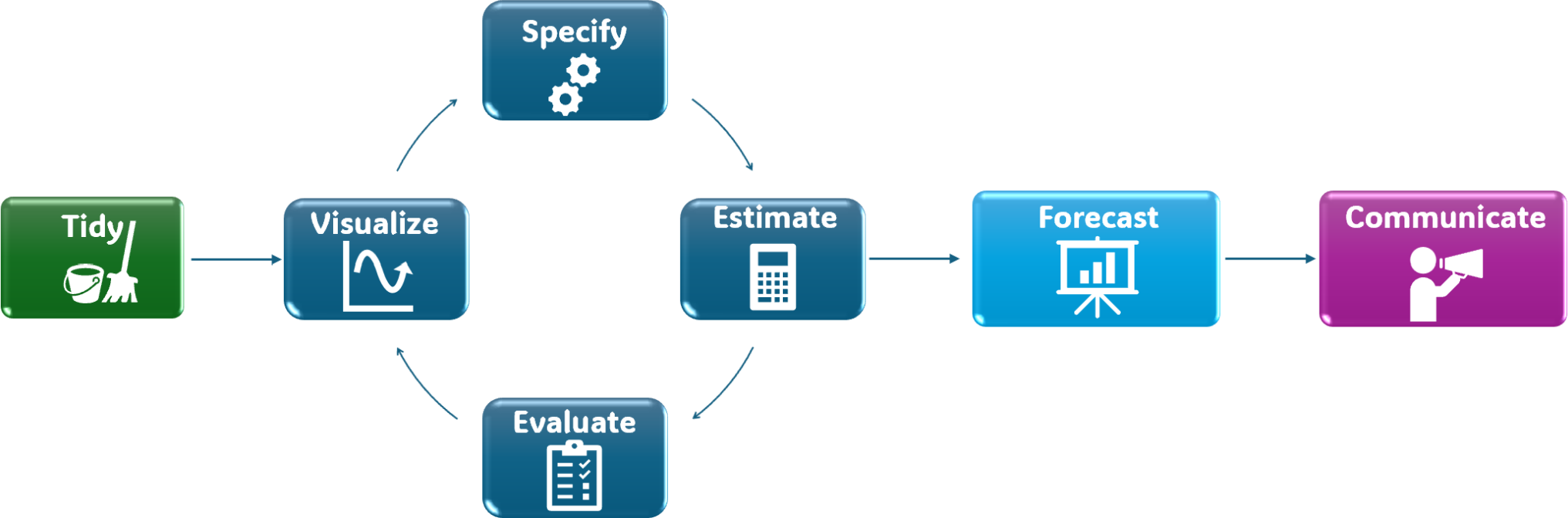
Foundations
Forecasting requires methodological discipline:
- Split the data (train/test)
- Establish benchmark models
- Forecast
- Measure accuracy
- Select a baseline
- Refit and produce the final forecast
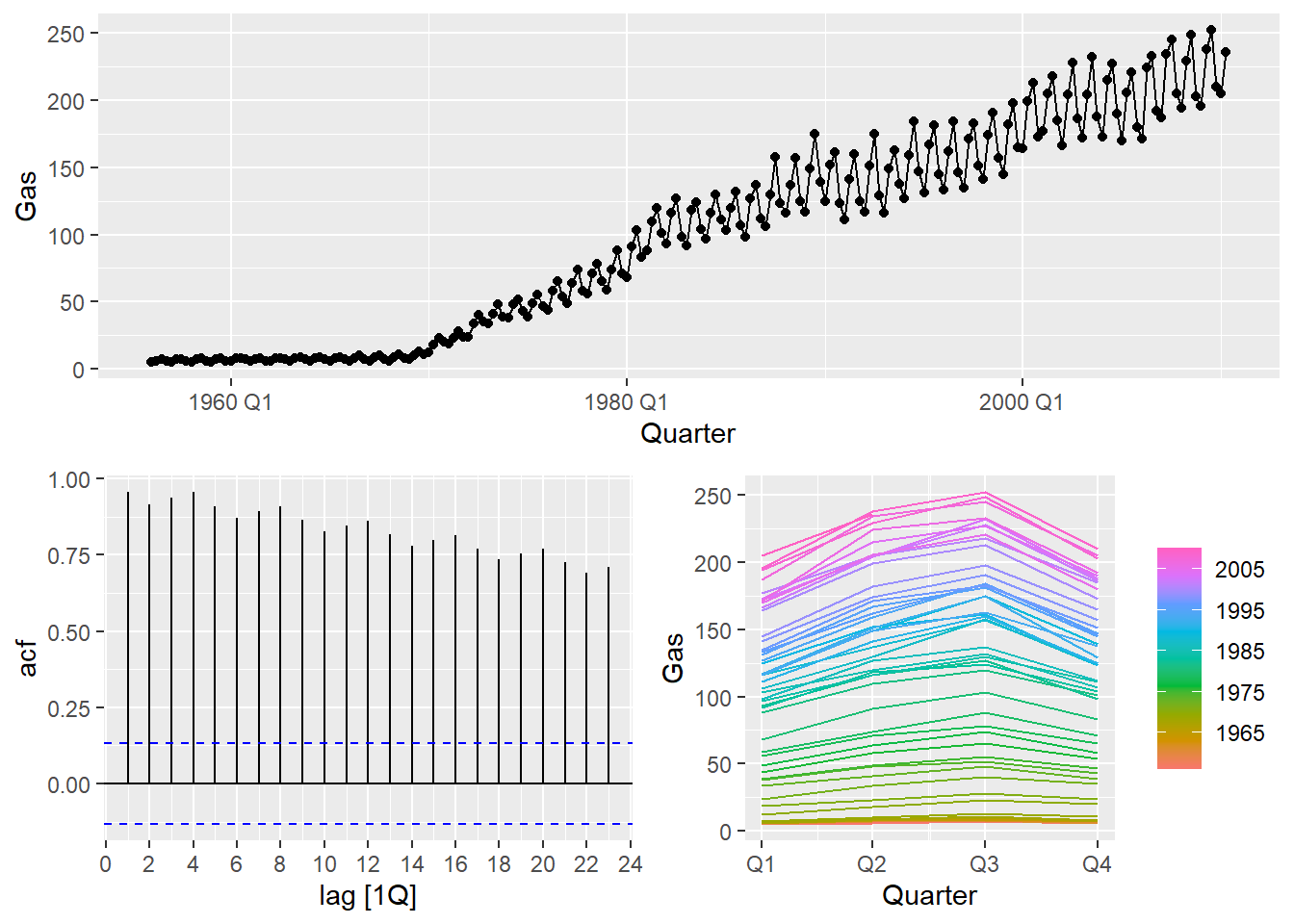
Example dataset
We use a built-in dataset from fpp3: aus_production.
- It is already a
tsibble - It contains multiple economic production series
- We focus on
Gas
Visualize
Train/test split
- Split the series into training and test sets.
- The test set length should match the forecast horizon.
For this example, we use the last 8 quarters as test data.
n_train n_test
212 6 Benchmark models
Before fitting complex models, we establish benchmarks.
Common benchmark methods in tidyverts:
- Mean method:
MEAN() - Naïve method:
NAIVE() - Seasonal naïve method:
SNAIVE() - Drift method:
RW(... drift())
Forecast
Generate forecasts with a horizon equal to the test set length.
(Optional) Plot forecasts:
Forecast accuracy
We measure forecast accuracy using forecast errors:
e_{T+h} = y_{T+h} - \hat{y}_{T+h|T}
Compute accuracy metrics:
Selection rule:
- Prefer models that perform well on MASE (scale-independent).
- For seasonal data,
snaiveis often a strong benchmark.
Error metrics
Using forecast errors, we can compute summary metrics:
| Scale | Metric | Description | Formula |
|---|---|---|---|
| Scale-dependent |
|
|
|
| Scale-independent |
|
|
|
Refit and forecast
Once a benchmark is selected based on the test set, refit it using all available data, then forecast the desired future horizon.
Example: refit snaive and forecast the next 8 quarters.
Communicate
Forecasting is not finished when numbers are produced.
Results must be communicated clearly and honestly.
Minimum communication checklist:
- Plot: history + forecast + prediction intervals
- Horizon: what the forecast period represents
- Baseline: state the benchmark model used
- Uncertainty: prediction intervals are essential
- Limitations: structural breaks, short samples, changing conditions
![]()
Time Series Forecasting