- 1
-
Replace
start_dateandend_datewith the desired date range for the training set.You can also use.to indicate the start or end of the series:filter_index(. ~ "end_date")orfilter_index("start_date" ~ .).
Forecasting Foundations
A tidy forecasting workflow
Visualize
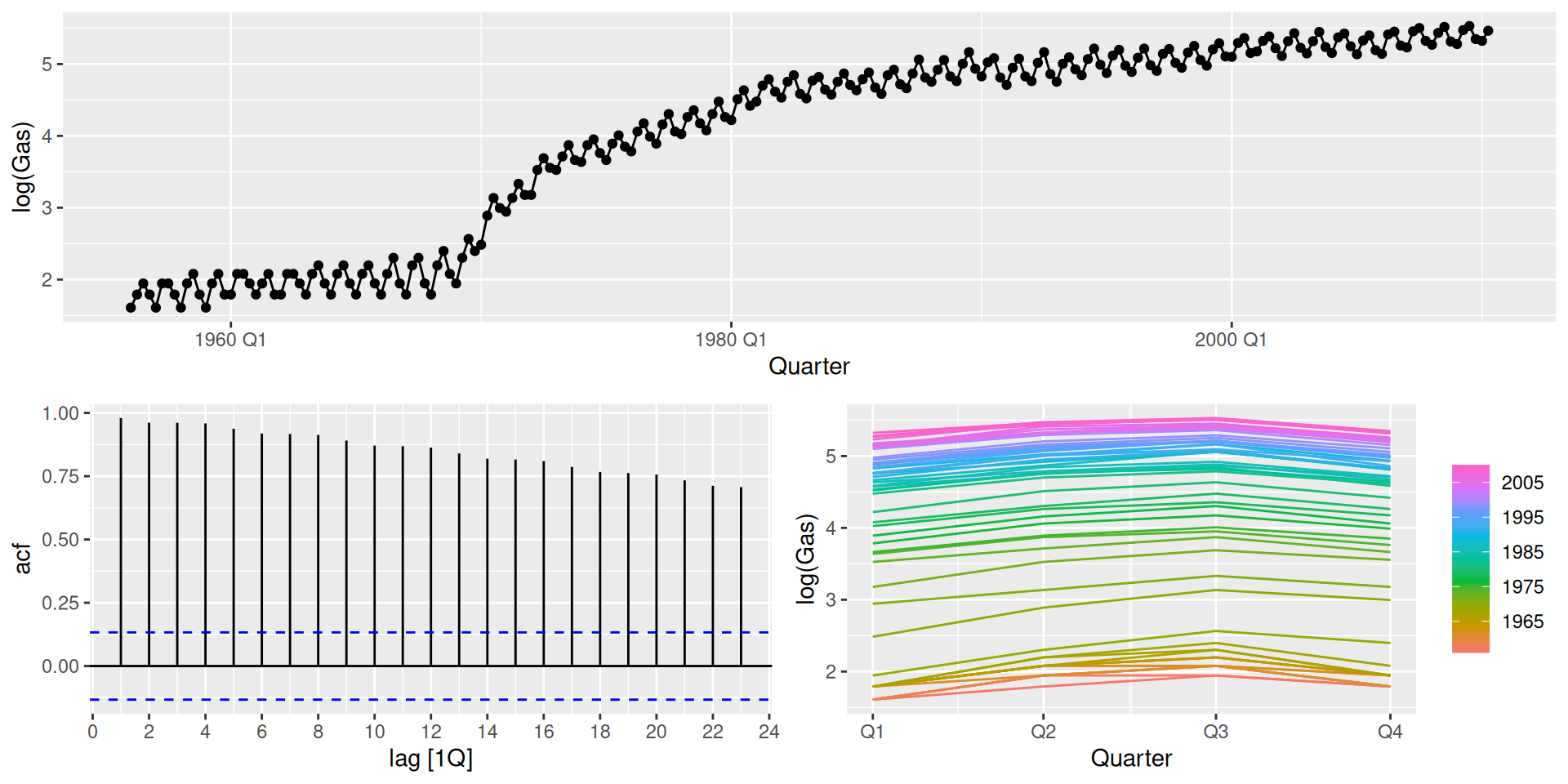
Plot the time series to identify patterns, such as trend and seasonality, and anomalies. This can help us choose an appropriate forecasting method. You can find many types of plots here.
Footnotes
i.e., if the TS has a monthly frequency, the index variable should be in
yearmonthformat. Other formats could beyearweek,yearquarter,year,date.Splitting the data into a training and test set is the minimum requirement for evaluating a forecasting model. If you want to avoid overfitting and get a more reliable estimate of the model’s performance, you should consider splitting the data into 3 sets: training, validation, and test sets. The validation set is used to tune model hyperparameters and select the best model, while the test set is used for the final evaluation of the selected model. For an even more robust evaluation of forecasting models, consider using time series cross-validation methods.
and store it in a
*_trainobject.and store the model table in a
*_fitobject.We will focus on innovation residuals whenever a transformation is used in the model.
and store the forecasts in a
*_fcstobject.Percentage errors are scale-independent, making them useful for comparing forecast accuracy across different series.
Scaled errors are also scale-independent and are useful for comparing forecast accuracy across different series.