The Forecasting Workflow using fable
2022-09-30

Visualization and EDA
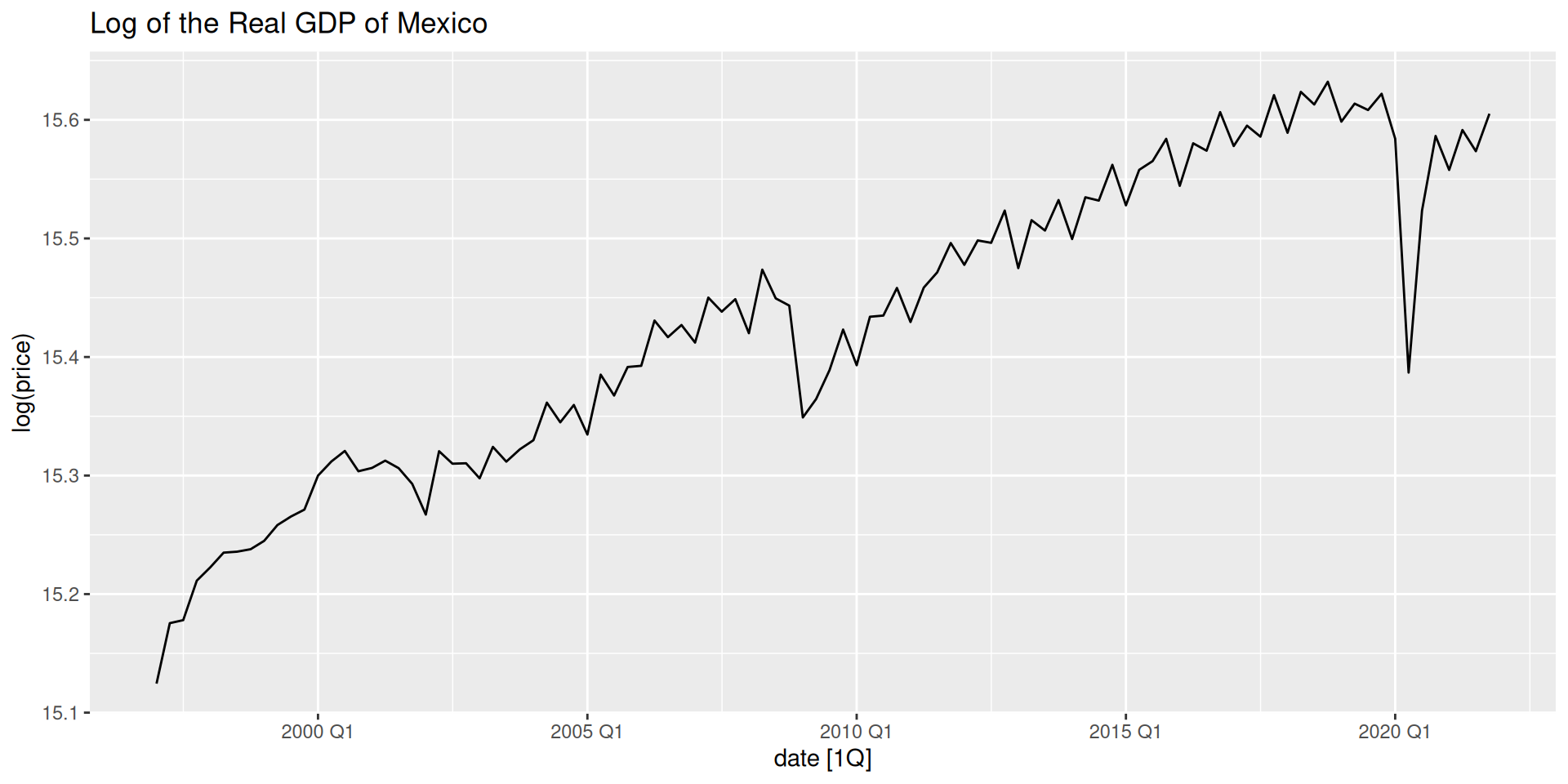
When performing time series analysis/forecasting, one of the first things to do is to create a time series plot.
We will explore it further with a season plot.
TS Decomposition
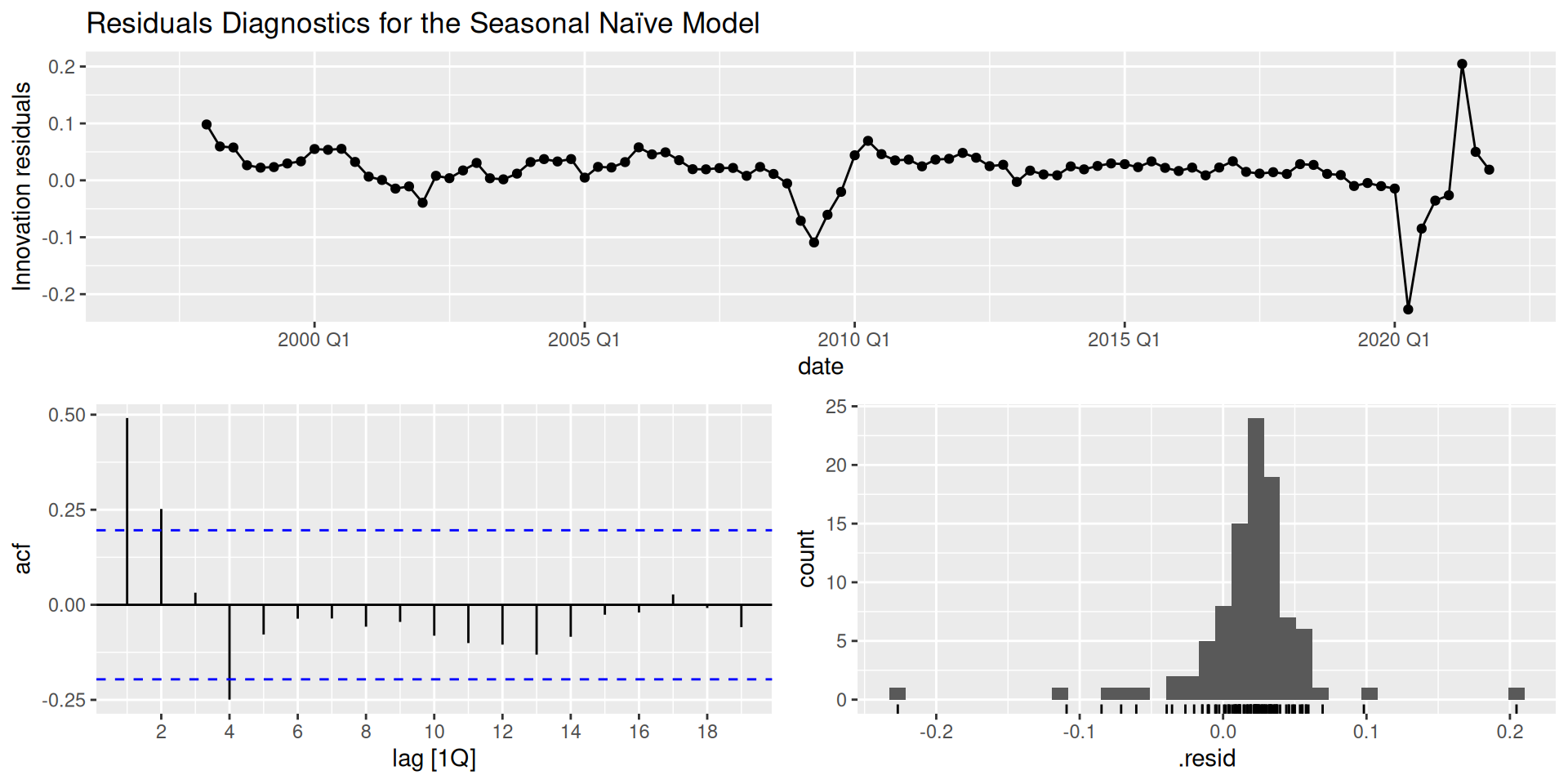
Residuals Diagnostics
Visual analysis
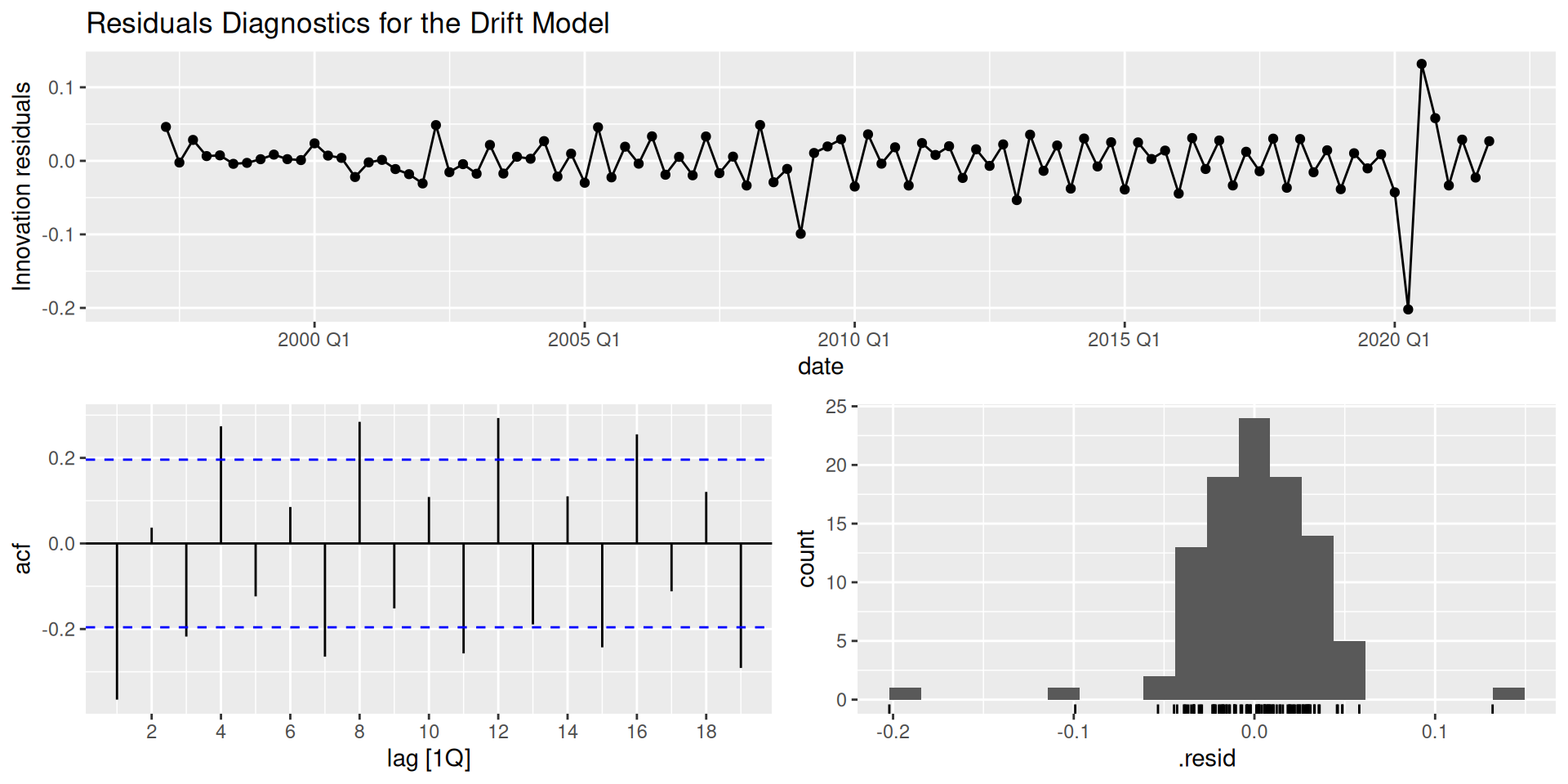
Tip
Here we expect to see:
- A time series with no apparent patterns (no trend and/or seasonality), with a mean close to zero.
- In the ACF, we’d expect no lags with significant autocorrelation.
- Normally distributed residuals.
Portmanteau tests of autocorrelation
Residuals interpretation
Both models produce sub optimal residuals:
The SNAIVE correctly detects the seasonality, however, its residuals are still autocorrelated. Moreover, the residuals are not normally distributed.
The drift model doesn’t account for the seasonality, and their distribution is a little bit skewed.
Hence, we will perform our forecasts using the bootstrapping method.
We can compute some error metrics on the training set using the accuracy() function:
The accuracy() function
The accuracy() function can be used to compute error metrics in the training data, or in the test set. What differs is the data that is given to it:
For the training metrics, you need to use the
mable(the table of models, that we usually store in_fit).For the forecasting error metrics, we need the
fable(the forecasts table, usually stored as_fcor_fcst), and the complete set of data (both the training and test set together).

Modeling using decomposition
We will perform a forecast using decomposition, to see if we can improve our results so far.
Note on decomposition_model()
Remember, when using decomposition models, we need to do the following:
Specify what type of decomposition we want to use and customize it as needed.
Fit a model for the seasonally adjusted data;
season_adjust.Fit a model for the seasonal component. R uses a
SNAIVE()model by default to model the seasonality. If you wish to model it using a different model, you have specify it.
- The name of the seasonal component depends on the type of seasonality present in the time series. If it has a yearly seasonality, the component is called
season_year. It could also be calledseason_week,season_day, and so on.
We can join this new model with the models we trained before. This way we can have them all in the same mable.
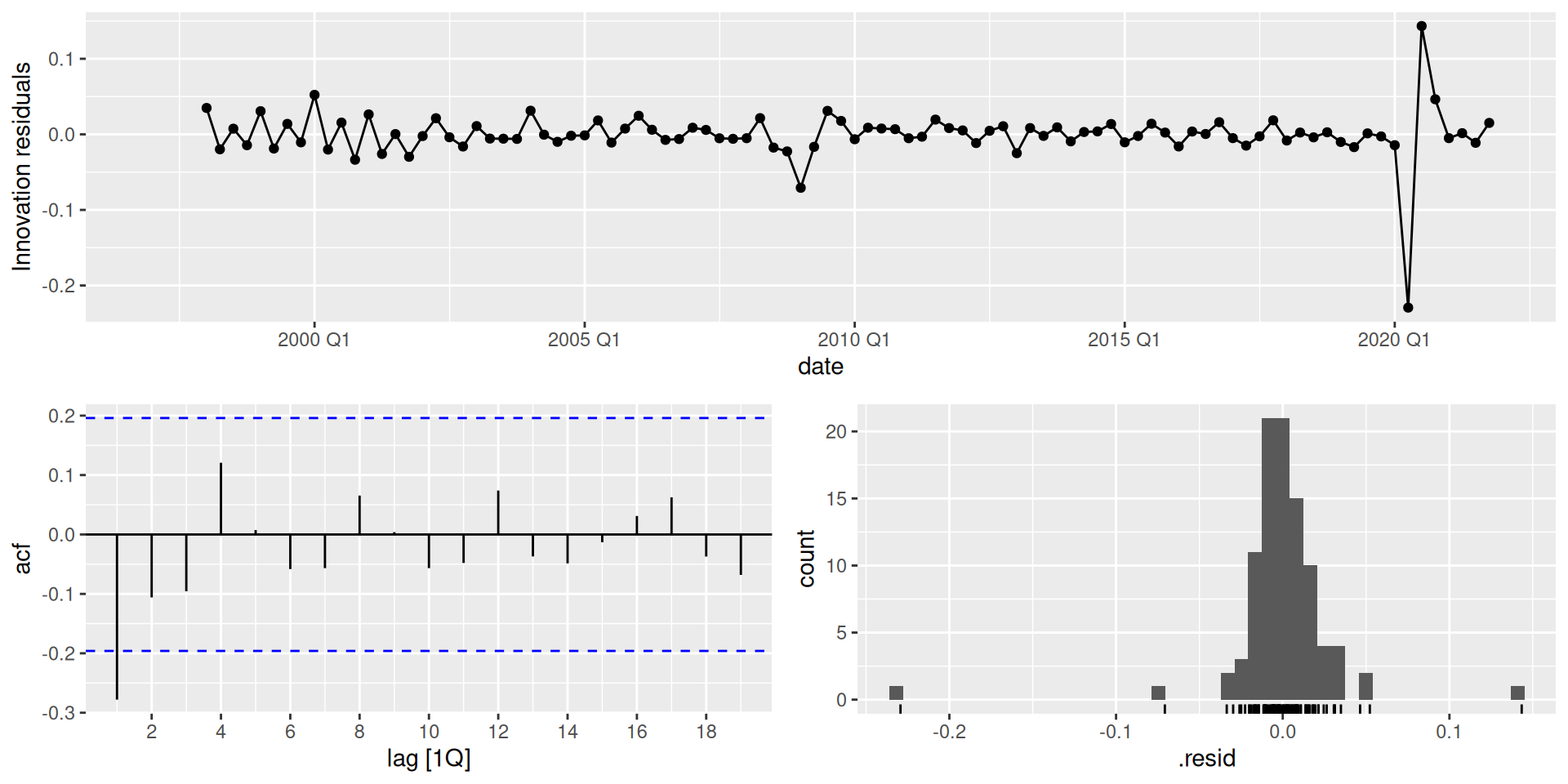
Residuals diagnostics
Forecasting on the test set
Once we have our models, we can produce forecasts. We will forecast our test data and check our forecasts’ performance.
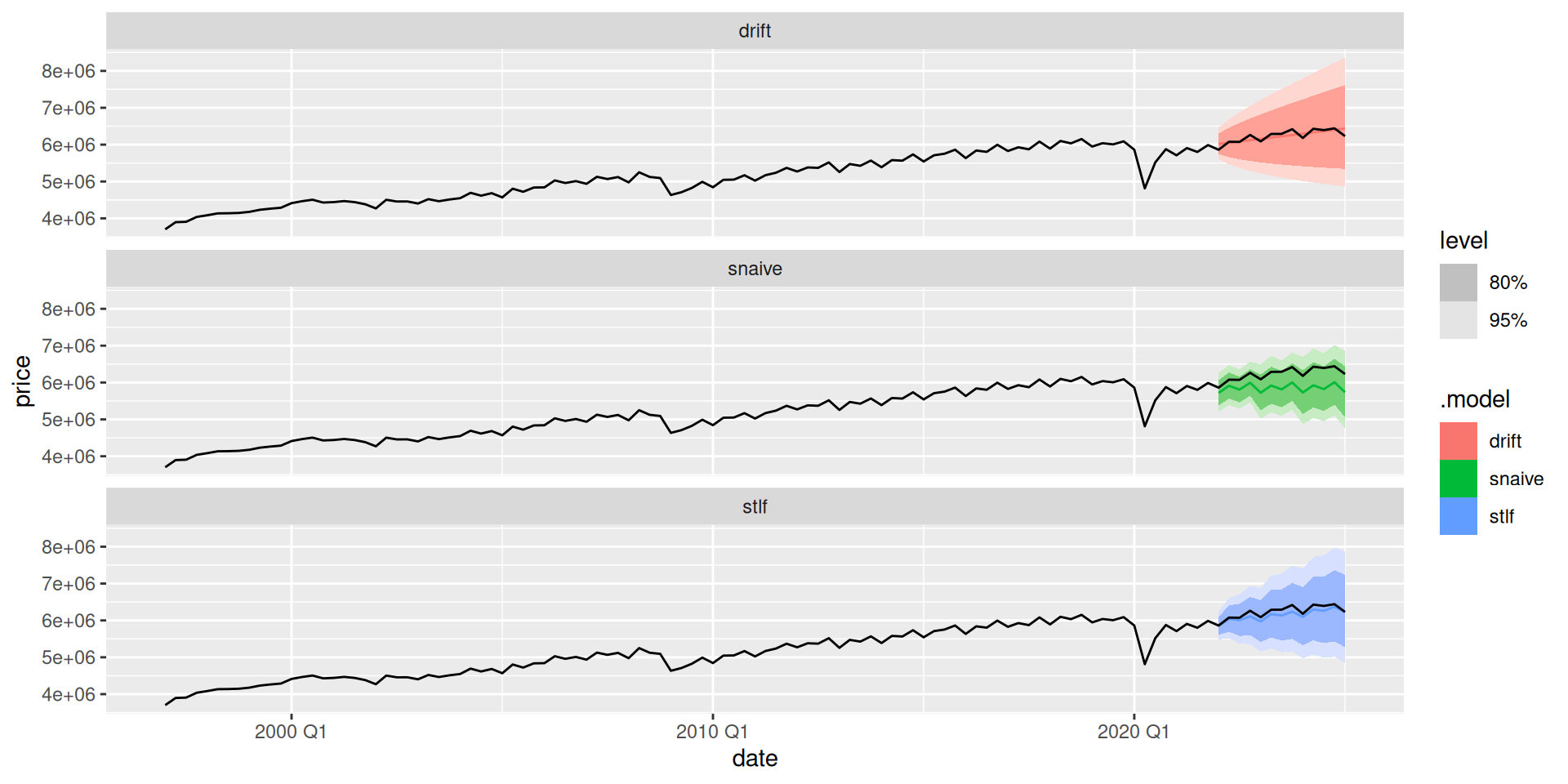
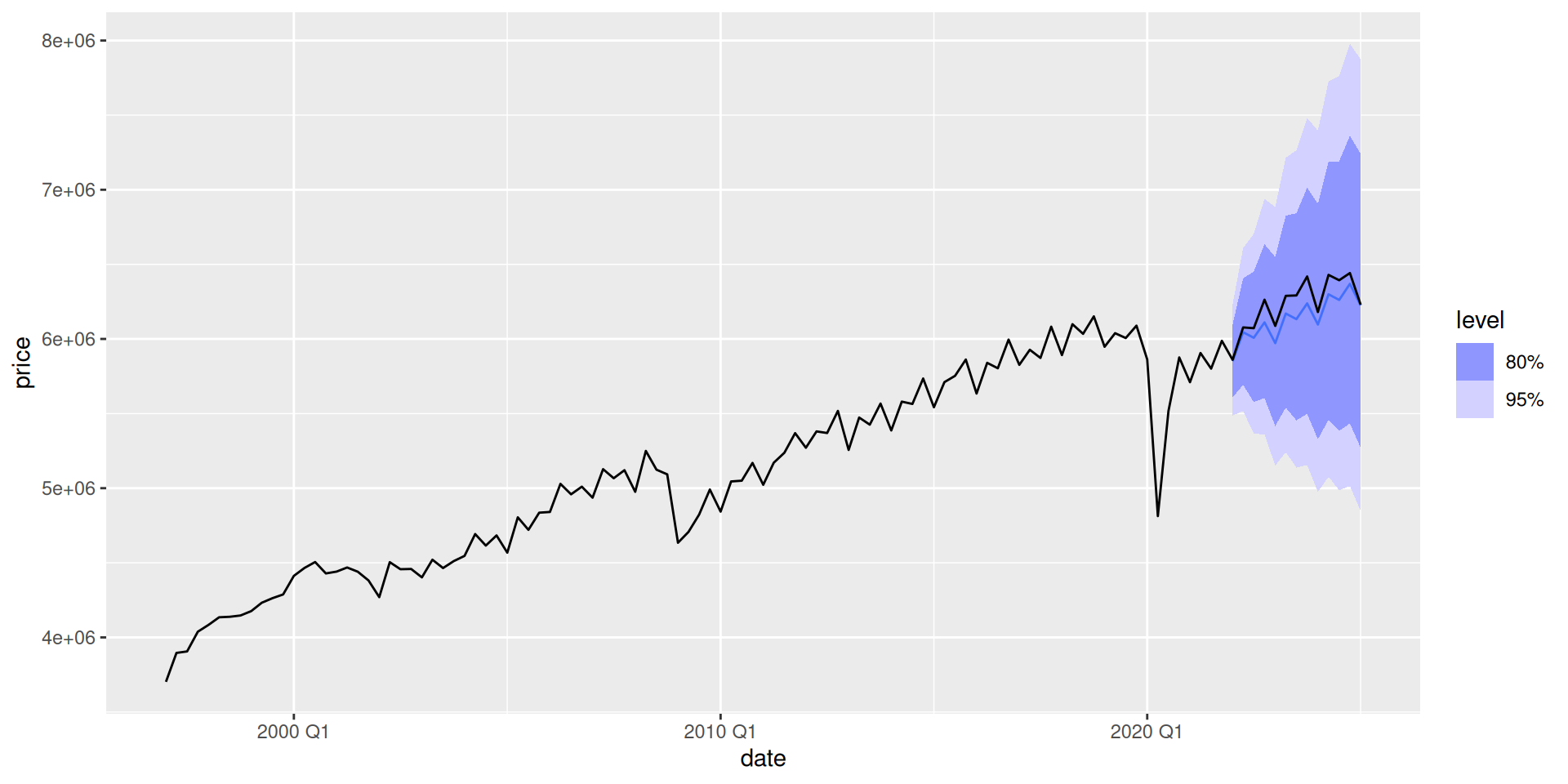
We now estimate the forecast errors:
Forecasting the future
We now refit our model using the whole dataset. We will only model the STL decomposition model, because the other two didn’t get a strong fit.
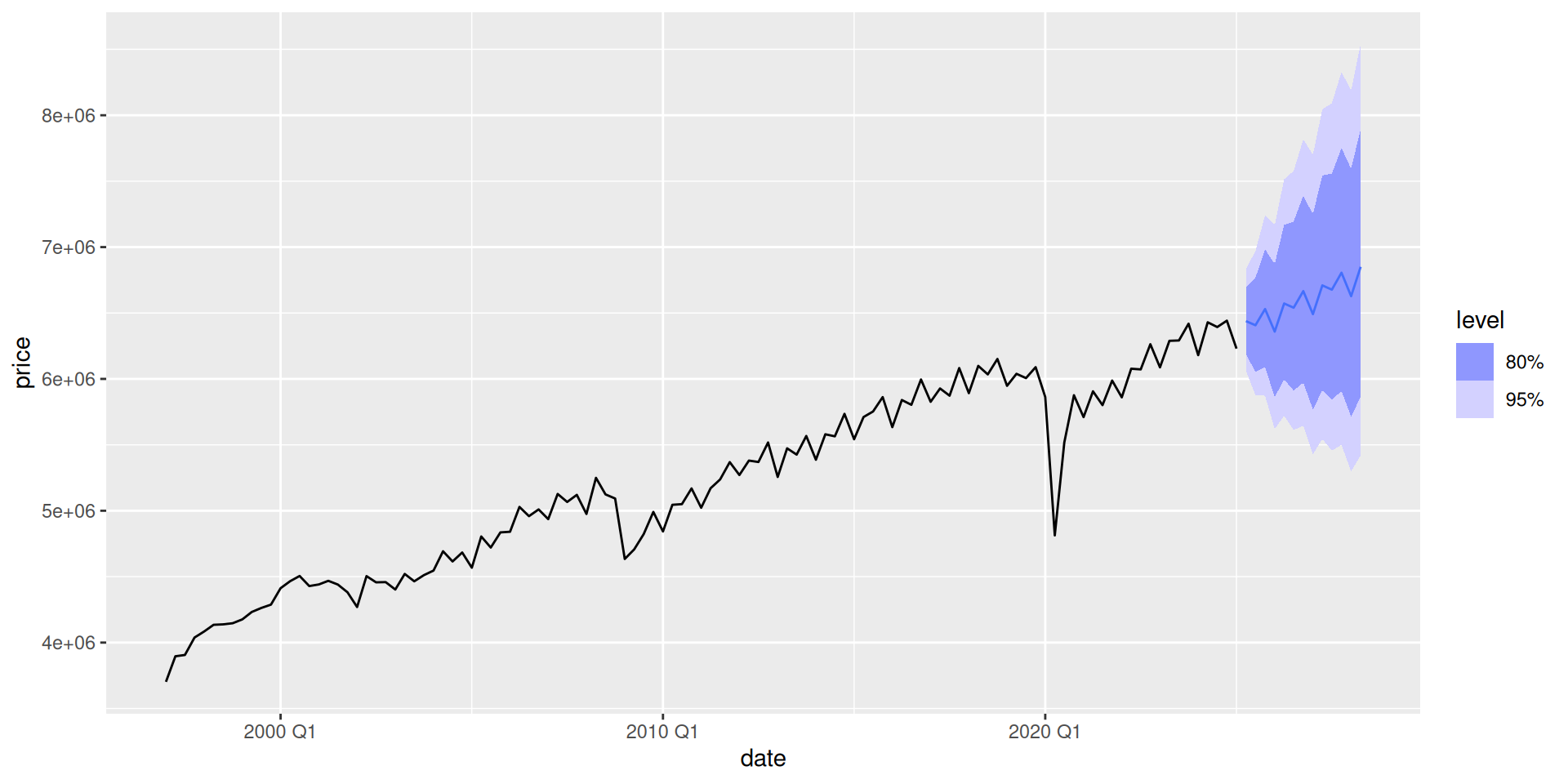
Footnotes
This will make it very convenient when calling your variables. RStudio will display all the options starting with
gdp_. We will usually use the following suffixes:_train: training set_fit: themable(table of models)_aug: the augmented table with fitted values and residuals_dcmp: for thedable(decomposition table), containing the components and the seasonally adjusted series of a TS decomposition._fcor_fcst: for thefable(forecasts table) that has our forecasts.![]()
The Mean Absolute Percentage Error is a percentage error metric widely used in professional environments.
Let
e_t = y_t - \hat{y}_t
be the error or residual.
Then the MAPE would be computed as
MAPE = \frac{1}{T}\sum_{t=1}^T|\frac{e_t}{y_t}| .
![]()

